Aurich Lawson
El jueves, la editorial de investigación Science anunció que todas sus revistas comenzarán a utilizar software comercial que automatiza el proceso de detección de imágenes manipuladas incorrectamente. Esta medida se produce hace muchos años cuando somos conscientes de que la transición a los datos y las publicaciones digitales ha hecho que sea cómicamente fácil cometer fraude en la investigación mediante la alteración de imágenes.
Si bien la medida es un primer paso importante, es importante reconocer las limitaciones del software. Si bien detectará algunos de los casos más atroces de manipulación de imágenes, los estafadores emprendedores pueden evitar fácilmente ser atrapados si saben cómo funciona el software. Lo cual, desgraciadamente, nos vemos obligados a describir (y, para ser justos, la empresa que ha desarrollado el software lo hace en su página web).
Fantástico fraude y cómo detectarlo.
Gran parte del fraude basado en imágenes que hemos visto surge de un dilema al que se enfrentan muchos científicos: realizar experimentos no es un problema, pero los datos que generan a menudo no son los que se desean. Quizás sólo funcionen los controles, o quizás los experimentos produzcan datos que no se pueden distinguir de los controles. Para los poco éticos, esto no representa un problema ya que nadie más que usted sabe qué imágenes provienen de qué muestras. Es relativamente sencillo presentar imágenes de datos reales como algo que no son.
Para concretar esto, podemos observar los datos de un procedimiento llamado mancha occidental, que utiliza anticuerpos para identificar proteínas específicas de una mezcla compleja que se ha separado según el tamaño de la proteína. Los datos típicos de transferencia Western se parecen a la imagen de la derecha, donde la oscuridad de las bandas representa proteínas que están presentes en diferentes niveles en diferentes condiciones.
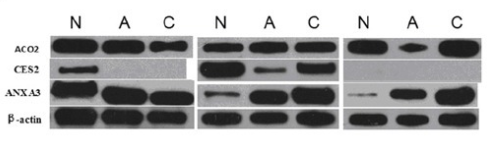
Un western blot como este, con muchas imágenes individuales eliminadas de su contexto original, facilita el fraude en la investigación.
Tenga en cuenta que las bandas son relativamente anodinas y están recortadas de imágenes más grandes de los datos sin procesar, separándolas de su contexto original. Es posible tomar bandas de un experimento y unirlas en una imagen de un experimento completamente diferente, generando de manera fraudulenta «evidencia» donde no existe ninguna. Se pueden hacer cosas similares con gráficos, fotografías de células, etc.
Dado que los datos son difíciles de conseguir y los estafadores suelen ser perezosos, en muchos casos, tanto las imágenes originales como las fraudulentas se derivan de datos utilizados para el mismo artículo. Para ocultar sus huellas, los investigadores poco éticos a menudo rotan, amplían, recortan o cambian el brillo/contraste de las imágenes y las usan más de una vez en el mismo artículo.
No todo el mundo es tan vago. Pero este reciclaje de imágenes es notablemente común y quizás la forma más frustrante de fraude en la investigación. Toda la evidencia está en el documento y, por lo general, es fácil de ver una vez que se señala. Pero, en primer lugar, puede resultar muy difícil detectarlo.
Ese desafío del «lugar en primer lugar» es la razón por la que la ciencia está recurriendo a un servicio llamado Proofig para que sea más fácil detectar problemas.