Microsoft Fabric es una solución integral software como servicio (SaaS) plataforma para análisis de datos. Está construido alrededor de un lago de datos llamado OneLake, y reúne componentes nuevos y existentes de Microsoft Power BI, Azure Synapse y Azure Data Factory en un único entorno integrado.
Microsoft Fabric abarca el movimiento de datos, el almacenamiento de datos, la ingeniería de datos, la integración de datos, la ciencia de datos, el análisis en tiempo real y la inteligencia empresarial, junto con la seguridad, la gobernanza y el cumplimiento de los datos. En muchos sentidos, Fabric es la respuesta de Microsoft a Google Cloud Dataplex. Al momento de escribir este artículo, Fabric está en versión preliminar.
Microsoft Fabric está dirigido a todos: administradores, desarrolladores, ingenieros de datos, científicos de datos, analistas de datos, analistas de negocios y gerentes. Actualmente, Microsoft Fabric está habilitado de forma predeterminada para todos los inquilinos de Power BI.
Microsoft Fabric Data Engineering combina chispa apache con Data Factory, lo que permite programar y organizar cuadernos y trabajos de Spark. Fabric Data Factory combina Power Query con la escala y la potencia de Azure Data Factory y admite más de 200 conectores de datos. Fabric Data Science se integra con Aprendizaje automático de Azure, que permite el seguimiento de experimentos y el registro de modelos. Fabric Real-Time Analytics incluye un flujo de eventos, un KQL (Lenguaje de consulta de Kusto) base de datos y un conjunto de consultas KQL para ejecutar consultas, ver resultados de consultas y personalizar resultados de consultas sobre datos. Si KQL es nuevo para usted, bienvenido al club.
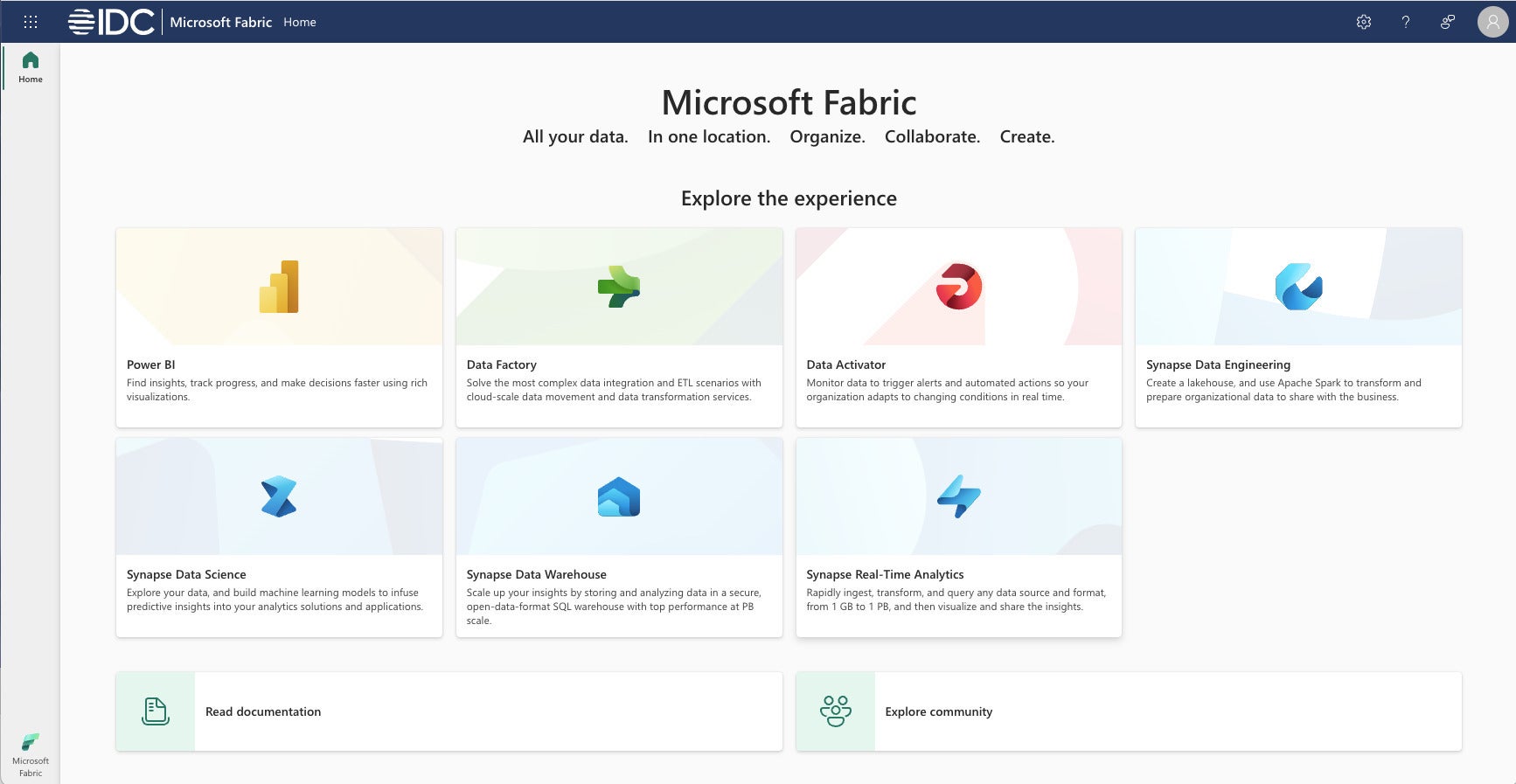 IDG
IDGPantalla de inicio de Microsoft Fabric. Tenga en cuenta los vínculos a Power BI, Data Factory, Data Activator, Synapse Data Engineering, Synapse Data Science, Synapse Data Warehouse y Synapse Real-Time Analytics.
un lago
OneLake es un lago de datos lógico y unificado para toda su organización; cada inquilino tiene un solo lago de datos. OneLake está diseñado para ser el único lugar para todos sus datos analíticos, de la misma manera que Microsoft quiere que use OneDrive para todos sus archivos. Para simplificar el uso de OneLake desde su escritorio, puede instalar el explorador de archivos OneLake para Windows.
OneLake se basa en Azure Data Lake Storage (ADLS) Gen2 y puede admitir cualquier tipo de archivo. Sin embargo, todos los componentes de datos de Fabric, como los almacenes de datos y los lagos de datos, almacenan sus datos automáticamente en OneLake en formato Delta (basado en Parquet apache), que también es el formato de almacenamiento utilizado por Ladrillos de datos de Azure. No importa si los datos fueron generados por Spark o SQL, todavía van a un único lago de datos en formato Delta.
Crear una casa de lago de datos OneLake es bastante sencilla: cambie a la vista Ingeniería de datos, cree y nombre una nueva casa de lago y cargue algunos archivos CSV en la parte de archivos del lago de datos.
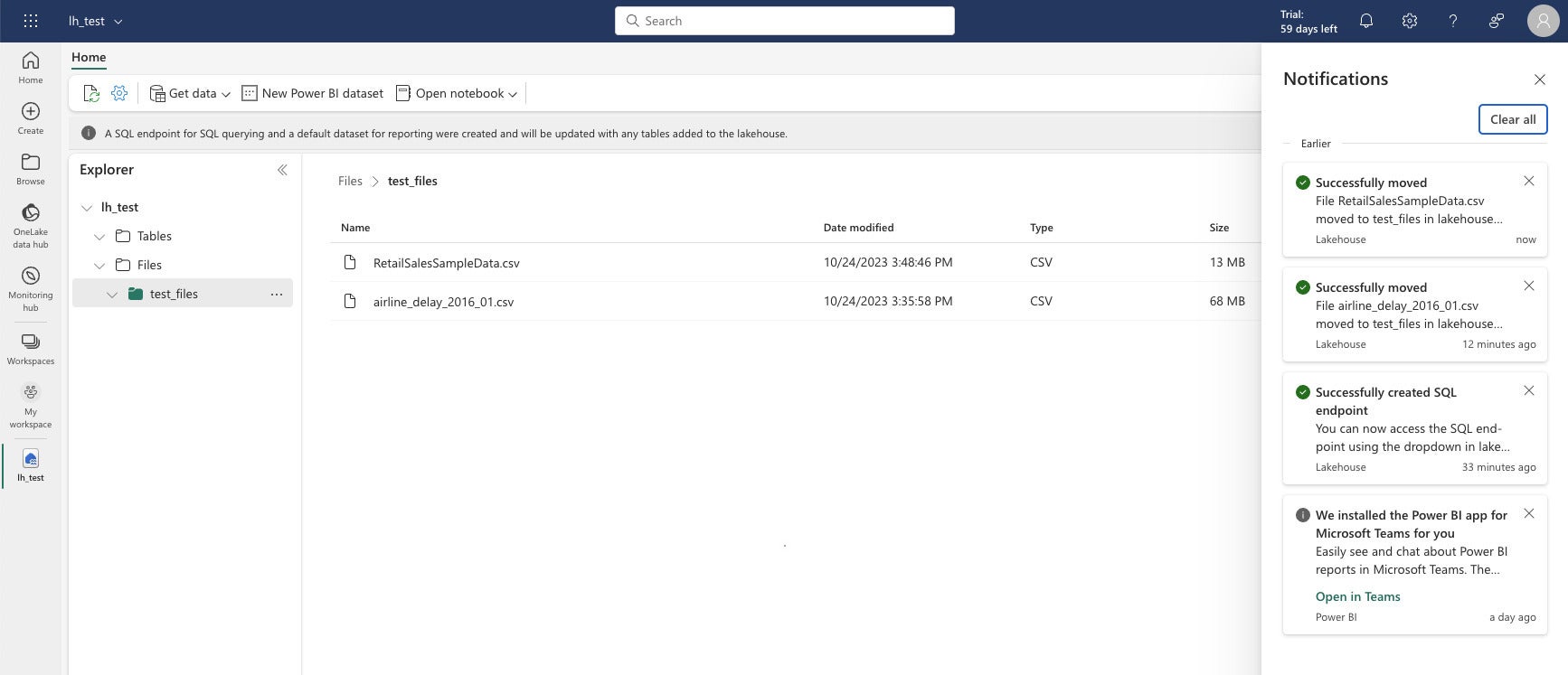 IDG
IDGEn la vista de ingeniería de datos de Microsoft Fabric, puede ver sus archivos y tablas. Las mesas están en formato Delta Parquet. Cuando selecciona un archivo, obtiene un menú de tres puntos para realizar operaciones en ese archivo, por ejemplo, cargarlo en una tabla.
Pasar de allí a tener mesas en la casa del lago puede (actualmente) ser más trabajo de lo que cabría esperar. Uno pensaría que el elemento del menú emergente Cargar en tablas haría el trabajo, pero falló en mis pruebas iniciales. Finalmente descubrí, con la ayuda del soporte técnico de Microsoft, que la función Cargar en tablas no sabe (en el momento de escribir este artículo) cómo manejar títulos de columnas con espacios incrustados. Ay. Todas las casas del lago de la competencia lo manejan sin problemas, pero Fabric es todavía en vista previa. Estoy seguro de que esta capacidad se agregará en el producto lanzado.
Conseguí que esa conversión funcionara con archivos CSV limpios. También pude ejecutar una consulta Spark SQL en un cuaderno en una tabla nueva.
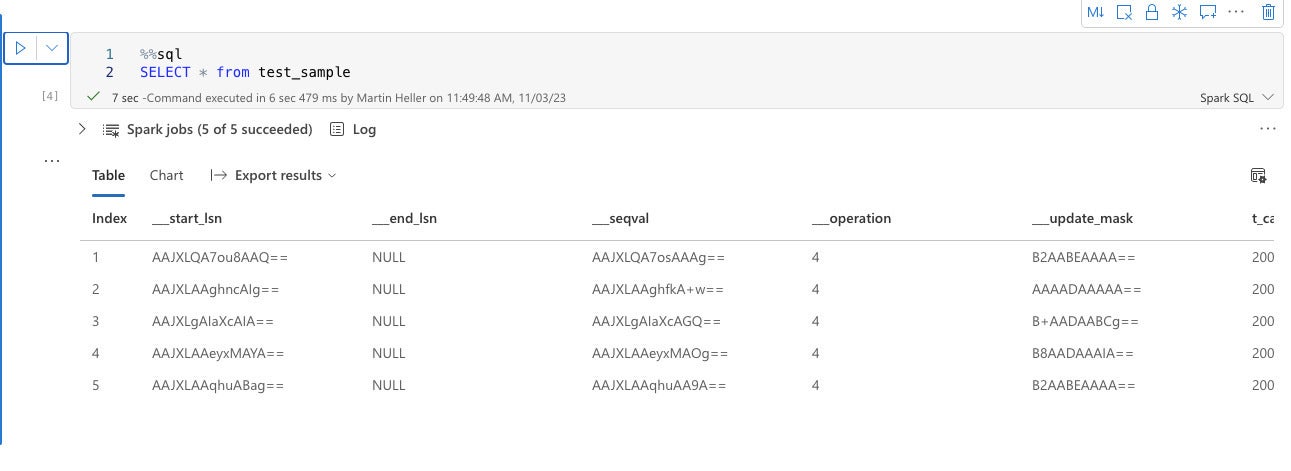 IDG
IDGLos cuadernos Fabric admiten tanto Python como SQL. Aquí estamos usando Spark SQL para mostrar el contenido de una tabla de la casa del lago OneLake.
Spark no es la única forma de ejecutar consultas SQL en las tablas de Lakehouse. Puede acceder a cualquier tabla de formato Delta en OneLake a través de un punto final SQL, que se crea automáticamente cuando implementa Lakehouse. Un punto final SQL hace referencia a la misma copia física de la tabla Delta en OneLake y ofrece una experiencia T-SQL. Básicamente se utiliza Azure SQL en lugar de Spark SQL.
Como verá más adelante, OneLake puede albergar almacenes de datos de Synapse, así como casas en el lago. Los almacenes de datos son mejores para usuarios con conocimientos de T-SQL, aunque los usuarios de Spark también pueden leer datos en los almacenes. Puede crear accesos directos en OneLake para que las casas de lago y los almacenes de datos puedan acceder a las tablas sin duplicar datos.
Energía BI
Power BI se ha ampliado para poder trabajar con tablas OneLake lakehouse (Delta). Como siempre, Power BI puede realizar análisis de datos básicos de inteligencia empresarial y generación de informes, e integrarse con Microsoft 365.
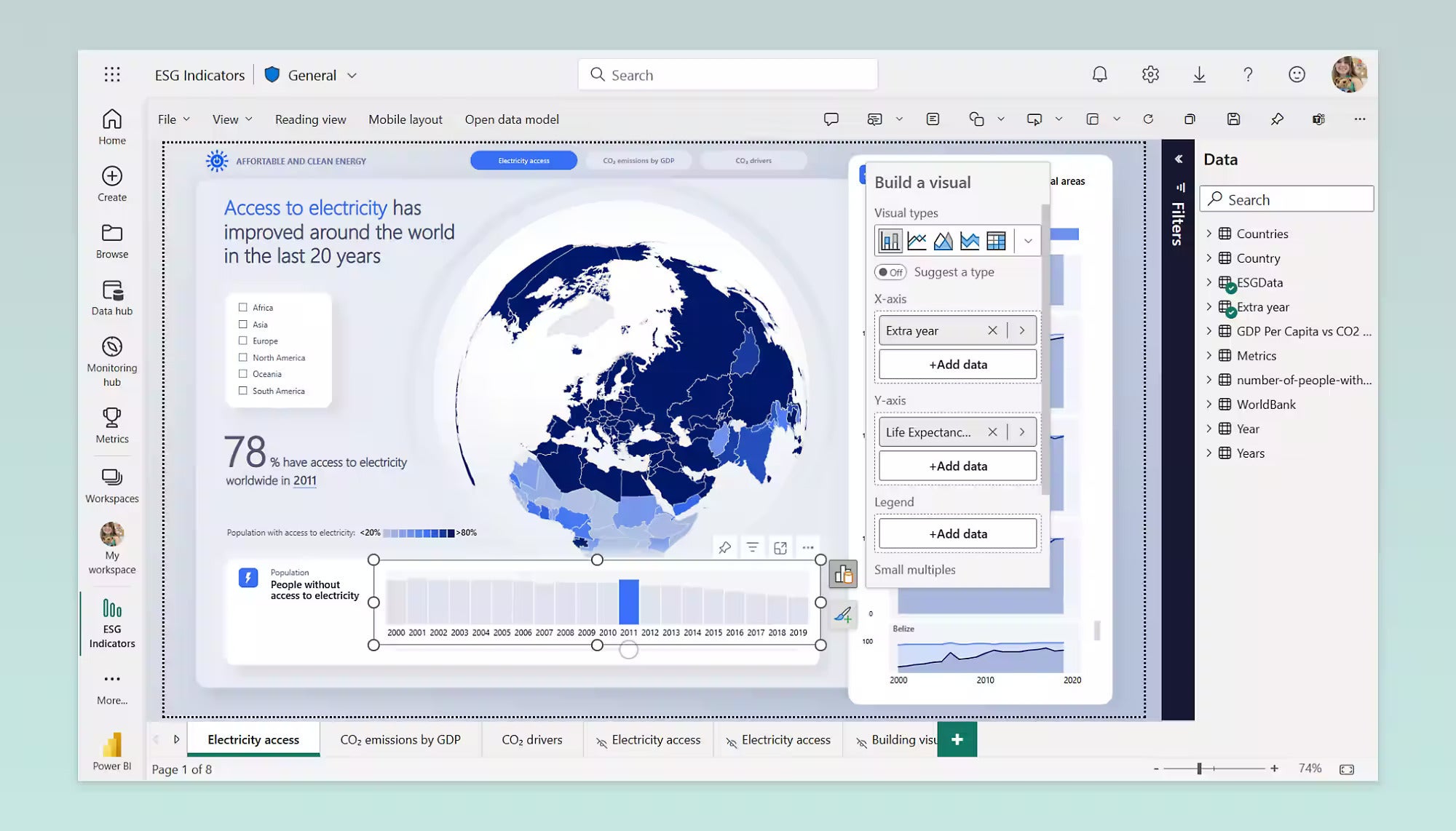 IDG
IDGUn informe de Power BI dentro de Microsoft Fabric. Prácticamente todas las características importantes de Power BI se han trasladado a Fabric.
Fábrica de datos
Data Factory en Microsoft Fabric combina capacidades de integración de datos ciudadanos y de integración de datos profesionales. Se conecta a unas 100 bases de datos relacionales y no relacionales, lagos, almacenes de datos e interfaces genéricas. Puede importar datos con flujos de datos, que permiten transformaciones de datos a gran escala con unas 300 transformaciones, usar el editor de Power Query y aplicar la extracción de datos con ejemplo de Power Query.
Probé un flujo de datos que importaba y transformaba dos tablas del conjunto de datos de Northwind. Me impresionaron las capacidades hasta que falló el paso final de publicación. OK, está en vista previa.
También puede utilizar canalizaciones de datos para crear flujos de trabajo de orquestación de datos que reúnan tareas como extracción de datos, carga en almacenes de datos preferidos, ejecución de cuadernos y ejecución de scripts SQL. Importé con éxito dos conjuntos de datos de muestra, días festivos y viajes en taxi de Nueva York, y los guardé en lagos de datos. No probé la capacidad de actualizar la canalización periódicamente.
Si necesita cargar datos locales en OneLake, eventualmente podrá crear una puerta de enlace de datos local y conectarla a un flujo de datos. Como solución temporal, puede copiar sus datos locales a la nube y cargarlos desde allí.
Activador de datos
Según Microsoft, Data Activator es una experiencia sin código en Microsoft Fabric para tomar acciones automáticamente cuando se detectan patrones o condiciones en los datos cambiantes. Supervisa los datos en los informes de Power BI y los elementos de Eventstreams, para cuando los datos alcancen ciertos umbrales o coincidan con otros patrones. Luego, automáticamente toma las medidas adecuadas, como alertar a los usuarios o iniciar flujos de trabajo de Power Automate.
Los casos de uso típicos de Data Activator incluyen publicar anuncios cuando las ventas en la misma tienda disminuyen, alertar a los gerentes de las tiendas para que retiren los alimentos de los congeladores defectuosos de las tiendas de comestibles antes de que se echen a perder y alertar a los equipos de cuentas cuando los clientes se atrasan, con límites de tiempo o valor personalizados por cliente.
Ingeniería de datos
La mayor parte de lo que hablé en la sección anterior de OneLake en realidad se incluye en la ingeniería de datos. La ingeniería de datos en Microsoft Fabric incluye Lakehouse, definiciones de trabajo de Apache Spark, cuadernos (en Python, R, Scala y SQL) y canalizaciones de datos (que se analizan en la sección Fábrica de datos anterior).
Ciencia de los datos
Data Science en Microsoft Fabric incluye modelos, experimentos y cuadernos de aprendizaje automático. Tiene alrededor de media docena de cuadernos de muestra. Elegí ejecutar el ejemplo del modelo de pronóstico de series de tiempo, que utiliza Python, el biblioteca profeta (de Facebook), flujo mly la función Fabric Autologging. La muestra de pronóstico de series de tiempo utiliza el Conjunto de datos de ventas de propiedades en Nueva Yorkque descarga y luego carga en un lago de datos.
Prophet utiliza un modelo de estacionalidad tradicional para la predicción de series temporales, un alejamiento refrescante de la tendencia hacia modelos de aprendizaje automático y aprendizaje profundo cada vez más complicados. El tiempo total de ejecución de las pruebas y las predicciones fue de 147 segundos, no tres minutos.
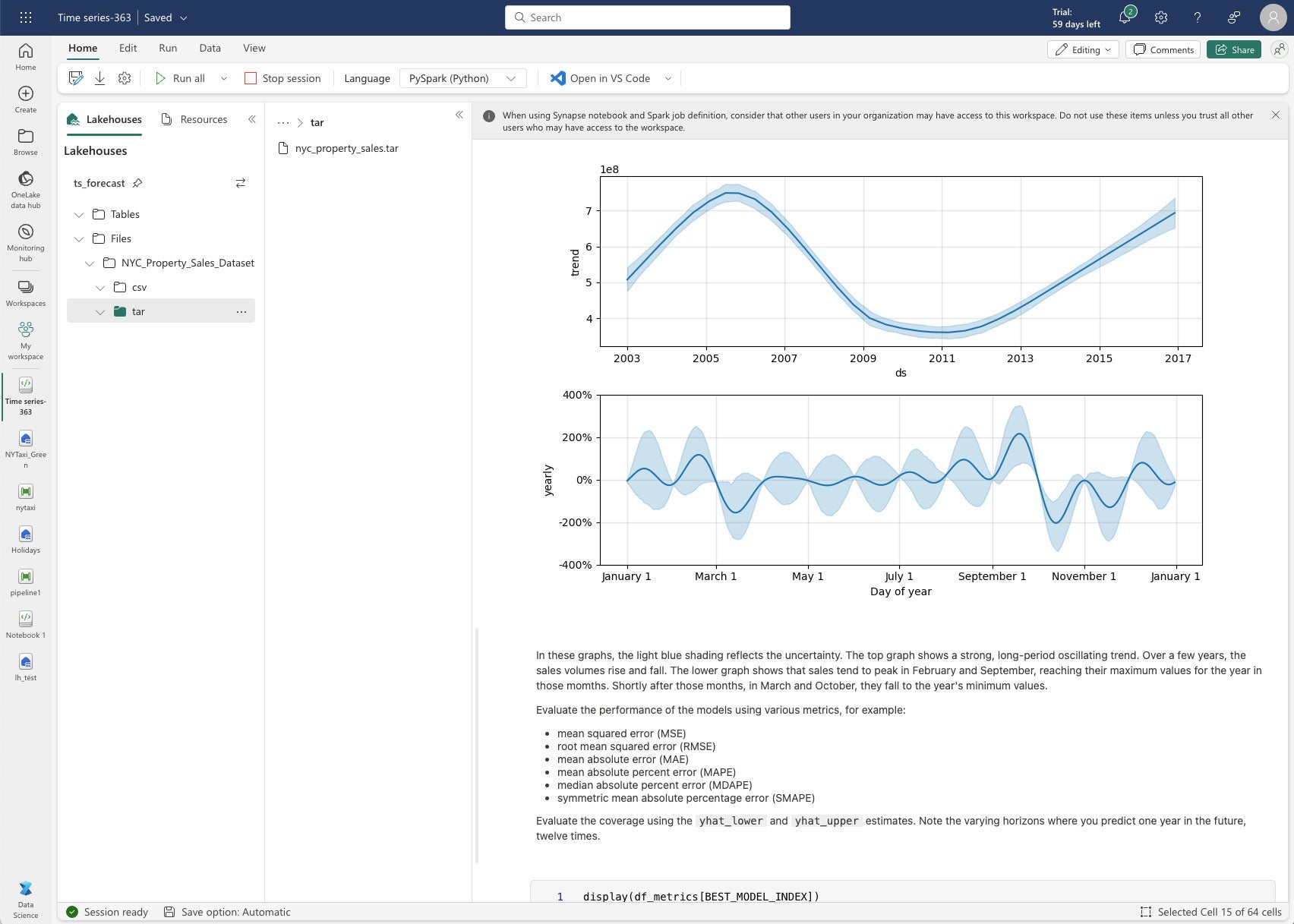 IDG
IDGPredicción de las ventas de propiedades después de ajustar los datos de ventas de propiedades de la ciudad de Nueva York a un modelo de estacionalidad de Prophet.
Almacén de datos
Data Warehouse en Microsoft Fabric tiene como objetivo converger los mundos de la lagos de datos y almacenes de datos. No es lo mismo que el punto final SQL de Lakehouse: el punto final SQL es un solo lectura almacén que se genera automáticamente al crearse desde un casa del Lago en Microsoft Fabric, mientras que el almacén de datos es un almacén de datos «tradicional», lo que significa que admite todas las capacidades transaccionales de T-SQL como cualquier almacén de datos empresarial.
A diferencia de SQL Endpoint, donde las tablas y los datos se crean automáticamente, Data Warehouse le da el control total de creando tablas y cargar, transformar y consultar sus datos en el almacén de datos mediante el portal Microsoft Fabric o comandos T-SQL.
Creé un nuevo almacén y lo cargué con datos de muestra proporcionados por Microsoft. Resulta ser otro conjunto de datos de viajes en taxi (de un año diferente), pero esta vez incluido en las tablas de almacén. Microsoft también proporciona algunos scripts SQL de muestra.
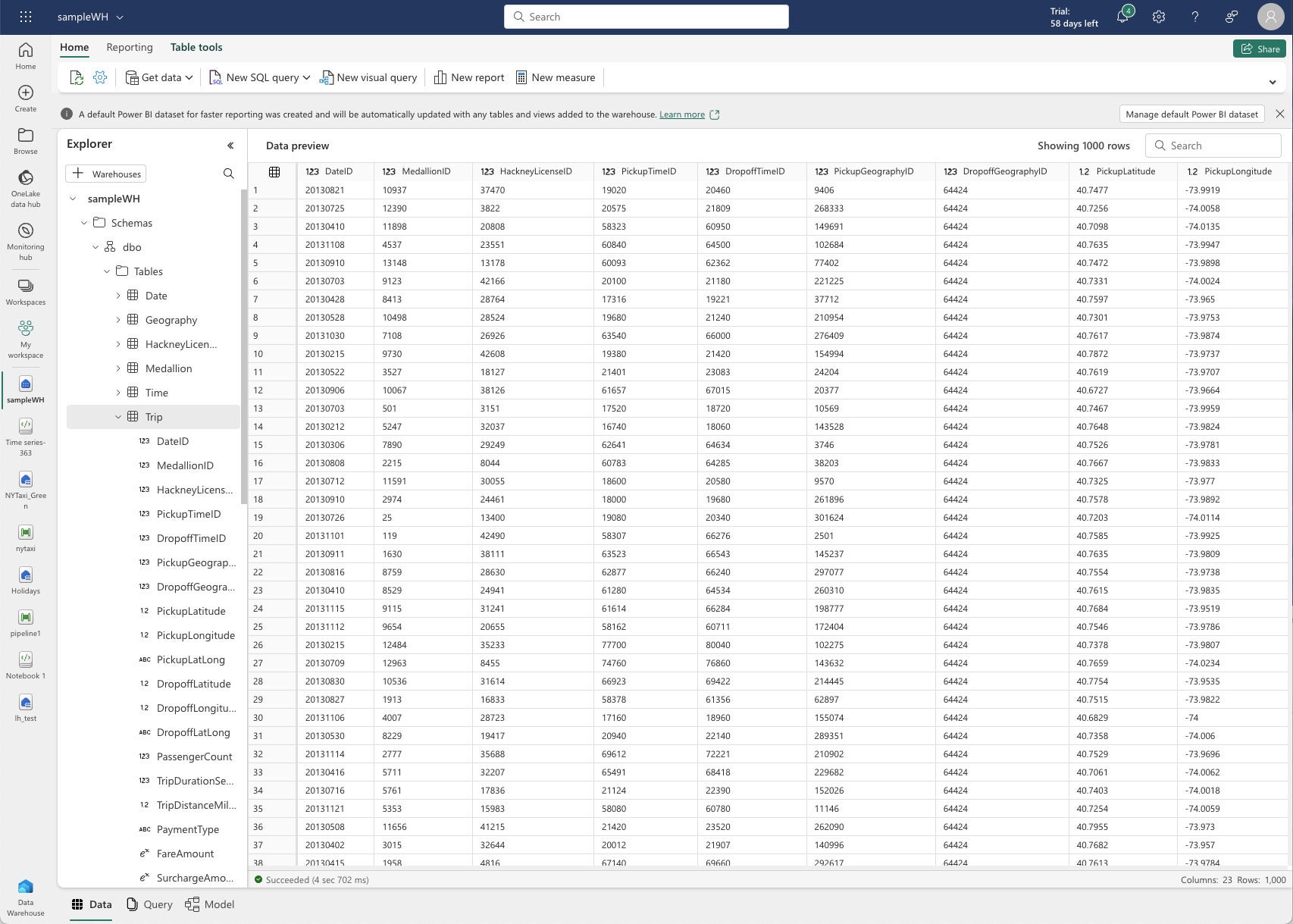 IDG
IDGVista previa de datos de Fabric Data Warehouse para una tabla. Tenga en cuenta los mensajes sobre el conjunto de datos de Power BI creado automáticamente en la parte superior.
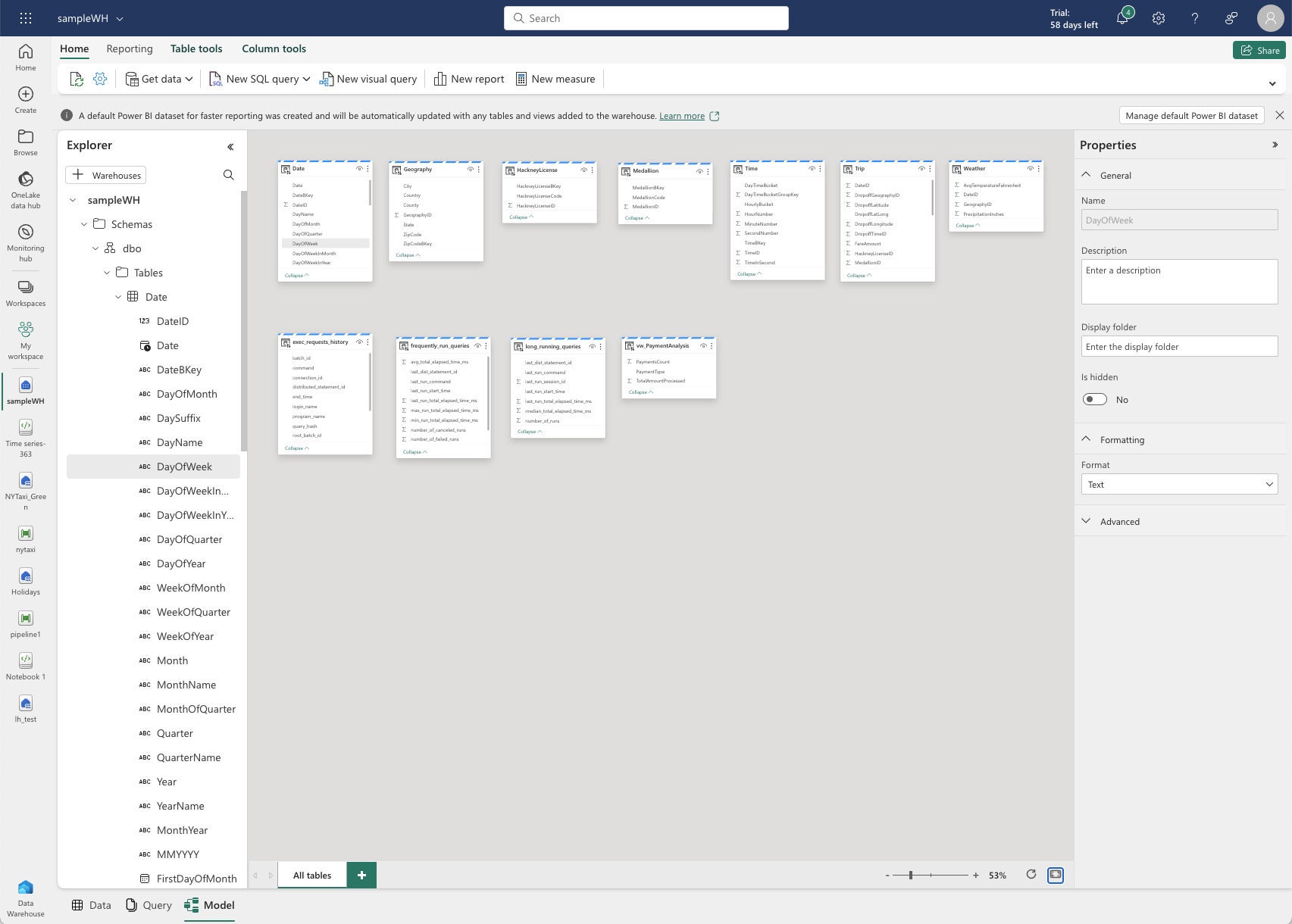 IDG
IDGVista del modelo Fabric Data Warehouse.
 IDG
IDGVista de consulta de Fabric Data Warehouse. Microsoft proporcionó el script SQL como parte del ejemplo.
Análisis en tiempo real
Real-Time Analytics en Microsoft Fabric está estrechamente relacionado con Azure Data Explorer, tan estrechamente que los vínculos de documentación para Real-Time Analytics actualmente van a la documentación de Azure Data Explorer. Me han asegurado que la documentación real de Fabric se está actualizando.
Uso de análisis en tiempo real y Azure Data Explorer Lenguaje de consulta de Kusto (KQL) bases de datos y consultas. Consultar datos en Kusto es mucho más rápido que el RDBMS transaccional, como SQL Server, especialmente cuando el tamaño de los datos crece a miles de millones de filas. Kusto lleva el nombre de Jacques Cousteau, el explorador submarino francés.
Utilicé una muestra de Microsoft, análisis meteorológico, para explorar KQL y análisis en tiempo real. Ese ejemplo incluye un script con varias consultas KQL.
 IDG
IDGLa galería de muestras de Fabric Real-Time Analytics ofrece actualmente media docena de ejemplos, con tamaños de datos que van desde 60 MB para análisis meteorológicos hasta casi 1 GB para viajes en taxi en Nueva York.
La consulta KQL para la siguiente captura de pantalla es interesante porque utiliza funciones geoespaciales y representa un gráfico de dispersión.
//We can perform Geospatial analytics with powerful inbuilt functions in KQL
//Plot storm events that happened along the south coast
let southCoast = dynamic({"type":"LineString","coordinates":[[-97.18505859374999,25.997549919572112],[-97.58056640625,26.96124577052697],[-97.119140625,27.955591004642553],[-94.04296874999999,29.726222319395504],[-92.98828125,29.82158272057499],[-89.18701171875,29.11377539511439],[-89.384765625,30.315987718557867],[-87.5830078125,30.221101852485987],[-86.484375,30.4297295750316],[-85.1220703125,29.6880527498568],[-84.00146484374999,30.14512718337613],[-82.6611328125,28.806173508854776],[-82.81494140625,28.033197847676377],[-82.177734375,26.52956523826758],[-80.9912109375,25.20494115356912]]});
StormEvents
| project BeginLon, BeginLat, EventType
| where geo_distance_point_to_line(BeginLon, BeginLat, southCoast) < 5000
| render scatterchart with (kind=map)
//Observation: Because these areas are near the coast, most of the events are Marine Thunderstorm Winds
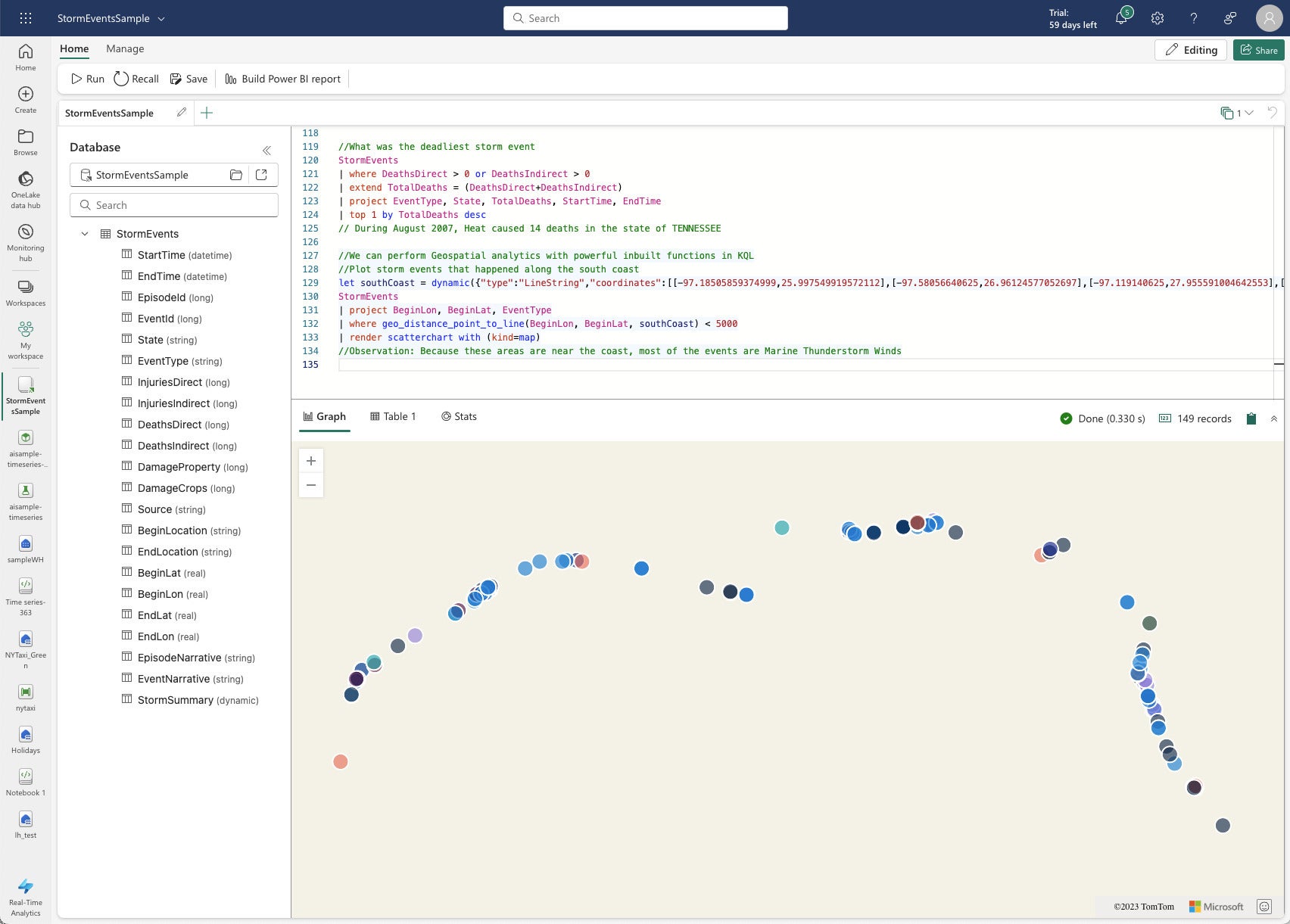 IDG
IDGA pesar de tener 60 MB de datos, esta consulta KQL geoespacial se ejecutó en un tercio de segundo.
Amplio alcance y análisis profundo
Si bien descubrí numerosos errores mientras exploraba la vista previa de Microsoft Fabric, también tuve una buena idea de su amplio alcance y sus profundas capacidades analíticas. Cuando esté completamente sacudido y desarrollado, bien podría competir con Google Cloud Dataplex.
¿Microsoft Fabric es realmente apropiado para todos? No tengo ni idea. Pero yo poder Digamos que Fabric hace un buen trabajo al permitirle ver solo su área de interés actual con el selector de vistas en la esquina inferior izquierda de la interfaz, lo que me recuerda la forma en que Adobe Photoshop sirve a sus diversos públicos (fotógrafos, retocadores, artistas, etc.). en). Desafortunadamente, Photoshop tiene la reputación bien ganada de no sólo tener mucho poder, sino también ser un oso para aprender. Queda por ver si Fabric desarrollará una reputación similar.
Copyright © 2024 IDG Communications, Inc.