
En Tubo de vapor desagregado mostramos cómo sus complementosque originalmente funcionaba sólo con el contenedor de datos extranjeros cargados en Postgres con baterías incluidas de Steampipe, ahora también están disponibles como distribuciones independientes que puede cargar en sus propias instancias de Postgres o SQLite. Ahora el propio Steampipe está desagregado: su servidor de panel y su ejecutor de pruebas han migrado a un nuevo proyecto de código abierto. tubo de potencia.
Cuando inicia Powerpipe, el valor predeterminado es una instancia local de Steampipe, por lo que los paneles y puntos de referencia existentes funcionan como siempre. El modificaciones que los impulsan obtienen sus datos de los mismos complementos, utilizando las mismas consultas SQL. Pero puedes usar Powerpipe. --database Argumento para especificar una cadena de conexión de Postgres, SQLite, DuckDB o MySQL.
¿Por qué desagregar Steampipe de esta manera? La filosofía Unix sostiene que una herramienta de software debe hacer bien una cosa y combinarse fácilmente con otras herramientas que respeten el mismo principio. Steampipe comenzó de esa manera, pero a medida que aparecieron el tablero y las capas de referencia, quedó claro que era necesario refactorizar. Para los ingenieros de desarrollo que utilizan la herramienta para visualizar y evaluar la infraestructura de la nube, tiene sentido desacoplar esas capas en componentes con interfaces bien definidas. Pero Powerpipe no es sólo para ellos. Entre el conjunto de nuevas modificaciones lanzadas con Powerpipe, hay una que visualiza datos biomédicos de ARNCentral a través de un punto final público de Postgres. Para ver esos paneles, instala el mod y luego inicia Powerpipe de esta manera:
powerpipe server --database postgres://reader:NWDMCE5xdipIjRrp@hh-pgsql-public.ebi.ac.uk:5432/pfmegrnargs
Los paneles ahora se pueden navegar en http://localhost:9033.
Por supuesto, puede conectar cualquier cliente de Postgres a ese punto final. Lo que Powerpipe aporta a la fiesta es un enfoque de código para visualizar y validar datos. Los widgets que controlan los paneles y los puntos de referencia están escritos en un lenguaje declarativo, clorhidrato, que complementa las consultas SQL declarativas que llenan esos widgets con datos. Todo su código HCL y SQL se encuentra en repositorios, bajo control de versiones, abierto al mismo tipo de colaboración que espera y disfruta para todos los demás artefactos de código.
Trabajar con ese código también es una experiencia fácil para los desarrolladores en otro sentido. Powerpipe observa sus archivos y reacciona instantáneamente cuando realiza cambios en el HCL que configura los widgets del panel o en el SQL que los completa.
 IDG
IDGGráficos de relaciones basados en SQL
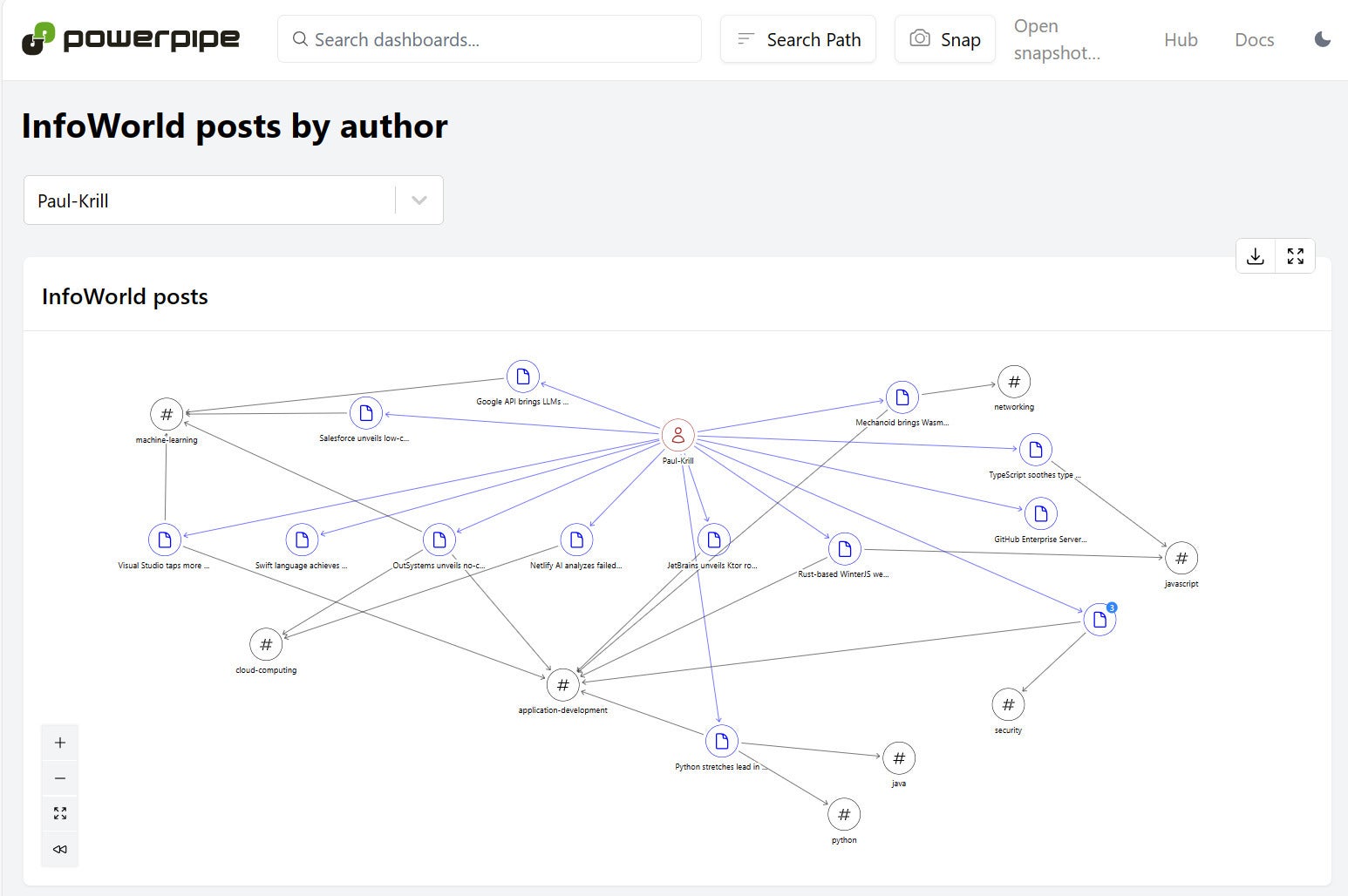
la suite de componentes del tablero Incluye todo lo que esperarías, incluidas tablas, gráficos, tarjetas de información y widgets de entrada. También incluye algunas cosas que quizás no esperes, en particular los nodos y bordes que forman gráficas de relaciones. A continuación se muestra un ejemplo que utiliza un widget de selección para elegir un autor de InfoWorld y luego crea un gráfico que relaciona al autor elegido con los artículos escritos y con las (quizás múltiples) categorías asociadas con cada artículo.
 IDG
IDGAsí es como se definen los nodos y los bordes. Dos de los nodos consultan categorías y autores, y el tercero utiliza el complemento RSS para consultar el feed RSS del autor seleccionado. Luego, dos bordes conectan los nodos. Uno relaciona los enlaces de los artículos con los autores, el otro relaciona los mismos enlaces con las categorías. Todo es solo SQL, aprovechado de una manera poco convencional.
-- enumerate categories
node {
category = category.category
sql = <<EOQ
select
category as id,
category as title
from
infoworld_categories()
EOQ
}
-- enumerate authors
node {
category = category.author
args = [self.input.authors.value]
sql = <<EOQ
select
author as id,
author as title
from
infoworld_authors()
where
author = $1
EOQ
}
-- list articles by author
node {
args = [self.input.authors.value]
category = category.post
sql = <<EOQ
with feed_links as materialized (
select
author,
'https://www.infoworld.com/author/' || author || '/index.rss' as feed_link
from infoworld_authors()
)
select
link as id,
title as title,
author,
jsonb_build_object(
'link', link,
'author', author,
'published', published
) as properties
from
rss_item r
join
feed_links f
using (feed_link)
where author = $1
order by
published desc
EOQ
}
-- relate articles to authors
edge {
args = [self.input.authors.value]
sql = <<EOQ
with feed_links as materialized (
select
author,
'https://www.infoworld.com/author/' || author || '/index.rss' as feed_link
from infoworld_authors()
)
select
link as to_id,
author as from_id
from
rss_item r
join
feed_links f
using (feed_link)
where
author = $1
EOQ
}
-- relate articles to categories
edge {
sql = <<EOQ
select
link as to_id,
category as from_id
from
infoworld_category_urls()
EOQ
}
Los usos más típicos de estos gráficos de relaciones ayudan a los ingenieros de Devops a comprender cómo encajan los elementos de sus infraestructuras en la nube, como por ejemplo en este gráfico que muestra cómo componentes de una implementación de Kubernetes(implementaciones, conjuntos de réplicas, pods, contenedores, servidores y nodos) se relacionan entre sí. Cada entidad en el gráfico tiene un hipervínculo a otro gráfico que profundiza en la entidad y detalla la infraestructura circundante.
 IDG
IDGEstas visualizaciones, que también están disponibles para AWS, Azury PCG, son una excelente manera de explorar y comprender sus arquitecturas de nube. Y las consultas que escribe para hacerlo son reutilizables. Puede hacer fluir los mismos datos en gráficos y tablas del panel.
Puntos de referencia y controles basados en SQL
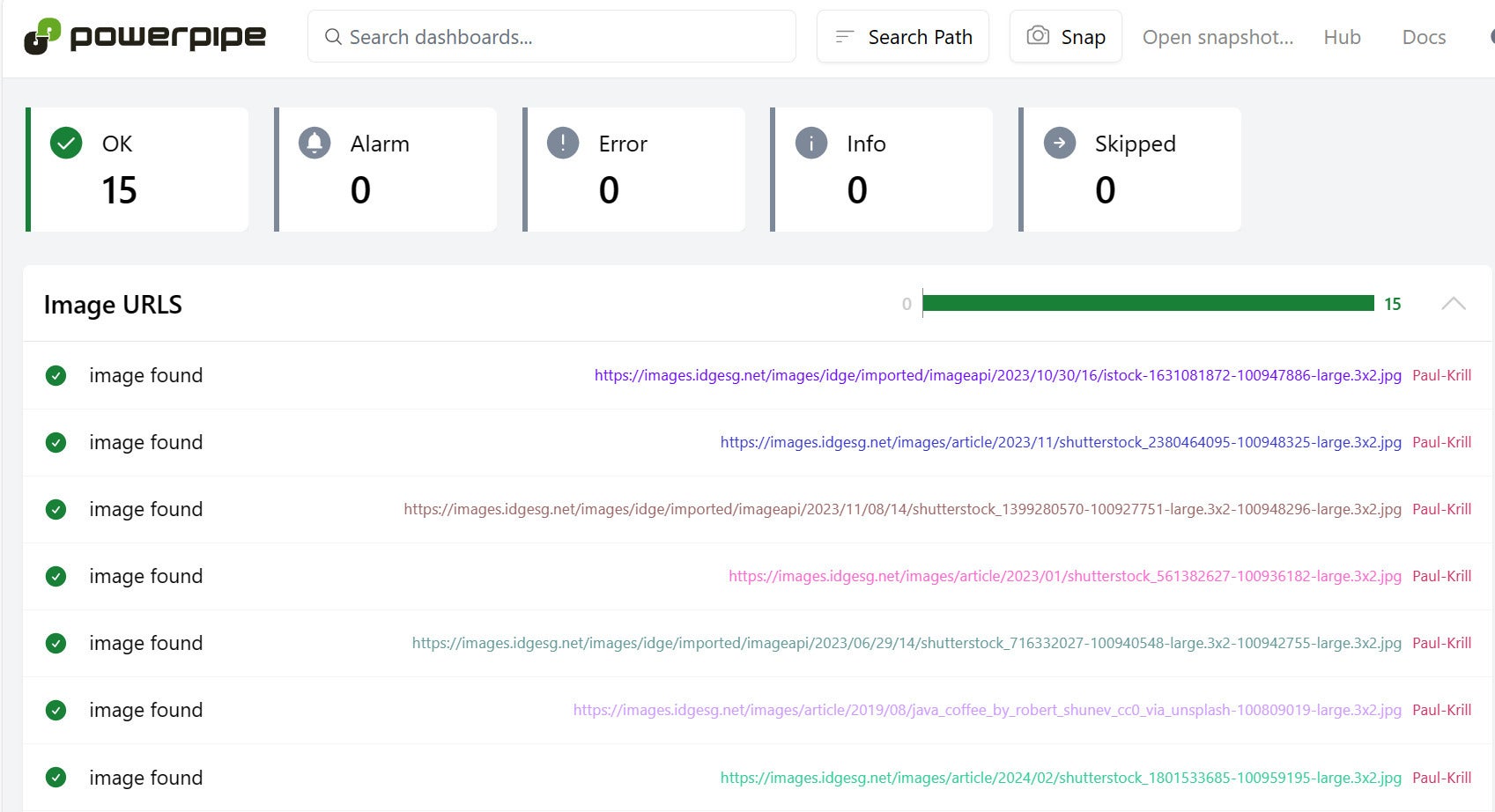
Powerpipe es también el motor que impulsa conjuntos de pruebas comparativas de cumplimiento, también para AWS, Azur, PCG, Kubernetes, y otros. Aquí hay un punto de referencia que valida las URL de imágenes incrustadas en el extensions campo de los canales RSS de InfoWorld.
 IDG
IDGY así es como se define. El punto de referencia incluye un control que ejecuta una consulta de varios pasos para seleccionar las URL de feeds para los autores, profundizar en cada elemento medios de comunicación etiqueta, luego verifique el código de respuesta HTTP para cada URL.
control "image_urls" {
title = "Image URLS"
sql = <<EOT
with authors as (
select
author,
'https://www.infoworld.com/author/' || author || '/index.rss' as feed_link
from
infoworld_authors()
limit 1
),
image_urls as materialized (
select
a.author,
r.extensions -> 'media' -> 'content' -> 0 -> 'attrs' ->> 'url' as url
from
authors a
join
rss_item r
using (feed_link)
),
response_codes as (
select
i.author,
n.url,
n.response_status_code
from
net_http_request n
join
image_urls i
using (url)
)
select
url as resource,
case when response_status_code = 200 then 'ok'
else 'alarm'
end as status,
case when response_status_code = 200 then 'image found'
else 'image not found'
end as reason,
substring(url from 1 for 150),
author
from response_codes
EOT
}
benchmark "feeds" {
title = "Check InfoWorld feeds"
children = [
control.image_urls
]
}
Puntos notables aquí:
- El
feed_linkLa columna devuelta por el primer CTE (expresión de tabla común) se une con su contraparte en el complemento RSS para recuperar el feed de cada autor. - Debido a que el back-end es Steampipe, que está basado en Postgres, los operadores JSONB de Postgres están disponibles para profundizar en el
mediaetiquetar y extraer la URL. - Cada
urlluego se une con la columna correspondiente del complemento de red-un cliente HTTP ¡envuelto como una tabla de base de datos! Para verificar el código de respuesta.
Un control es simplemente una consulta SQL que devuelve el columnas requeridas status, reasony resource. Puede pensar en un control como una prueba unitaria para datos, con Powerpipe como ejecutor de pruebas.
Estos controles suelen admitir conjuntos de cumplimiento estándar: CIS, FedRamp, GDPR, HIPAA, NIST, PCI, SOC 2 y más. Mods como Cumplimiento de AWS ofrecer un soporte amplio y profundo para estos, basándose en la cobertura API igualmente amplia y profunda proporcionada por los complementos de Steampipe como el de AWS.
Pero puedes crear mods de referencia para validar cualquier tipo de datos, dondequiera que se encuentren: en tablas efímeras pobladas por servicios en la nube a través de complementos, o en tus propias bases de datos como tablas nativas.
Paneles de control y puntos de referencia como código
Ya sea que esté visualizando datos con tablas, cuadros y gráficos interactivos, o validando datos usando controles, el modelo es el mismo. Utiliza consultas SQL para adquirir los datos y widgets HCL para mostrarlos, con edición en vivo en ambos casos. El código vive en paquetes llamados modificaciones que tu puedes instalar, creary remezclar.
Al igual que el producto Steampipe del que se desacopló, Powerpipe es un binario único que puede ejecutar localmente, en una máquina virtual en la nube o en una canalización de CI/CD. Y al igual que Steampipe, está disponible en formato alojado en Tubos de rodaballo donde puede colaborar con su equipo y compartir instantáneas de paneles y puntos de referencia.
Los conjuntos existentes de paneles y puntos de referencia de Powerpipe se centran en lo que más necesitan los desarrolladores: un lenguaje de consulta estándar, con acceso en vivo a las API de la nube, integrado en contenedores HCL que se encuentran en repositorios junto con el resto del código administrado. Ese es el punto ideal, pero con la separación de Steampipe ahora puedes usar las mismas tecnologías de manera más amplia.
Copyright © 2024 IDG Communications, Inc.




