
Opinión del editor: Los investigadores han descubierto una manera de tomar fotografías con los sensores de luz ambiental en la mayoría de los dispositivos móviles y computadoras portátiles. El estudio ha generado más que unos pocos titulares que incitan al miedo y provocan clics. Si bien los hallazgos son fascinantes y demuestran un potencial de abuso por parte de malos actores, su viabilidad como vector de ataque está severamente limitada con la tecnología actual.
Investigadores del Laboratorio de Ciencias de la Computación e Inteligencia Artificial (CSAIL) del MIT han desarrollado un método para capturar imágenes utilizando únicamente el sensor de luz ambiental que se encuentra en la mayoría de los dispositivos móviles y en muchas computadoras portátiles. El estudiar «Imagen de amenazas a la privacidad desde un sensor de luz ambiental» sugiere una posible amenaza a la seguridad ya que, a diferencia de la cámara para selfies, no hay configuraciones para apagar el componente. Las aplicaciones tampoco necesitan obtener el permiso del usuario para usarlas.
«La gente conoce las cámaras para selfies en portátiles y tabletas y, a veces, utiliza bloqueadores físicos para taparlas», dice el estudiante de doctorado de CSAIL Yang Liu, coautor del artículo de investigación publicado en enero en Science Advances. «Pero en el caso del sensor de luz ambiental, la gente ni siquiera sabe que una aplicación está usando esos datos. Y este sensor siempre está encendido».
Normalmente, no muchas aplicaciones utilizan el sensor de luz, ya que solo proporciona datos sobre cuánta luz le llega, lo que limita su utilidad. Su función principal es proporcionar datos de luz ambiental al sistema operativo para el ajuste automático del brillo de la pantalla, pero tiene una API. Para que los desarrolladores puedan acceder a él y utilizarlo. Por ejemplo, la aplicación podría usar la API para activar un modo de poca luz. Las aplicaciones de cámara en la mayoría de los dispositivos hacen esto.
Click para agrandar
Capturar una imagen es mucho más complicado ya que es esencialmente un sensor de un solo píxel sin lente que mide la luminancia a aproximadamente cinco «cuadros» por segundo. Para superar esta discapacidad, los investigadores sacrificaron la resolución temporal por la resolución espacial, lo que les permitió reconstruir una sola imagen a partir de datos mínimos.
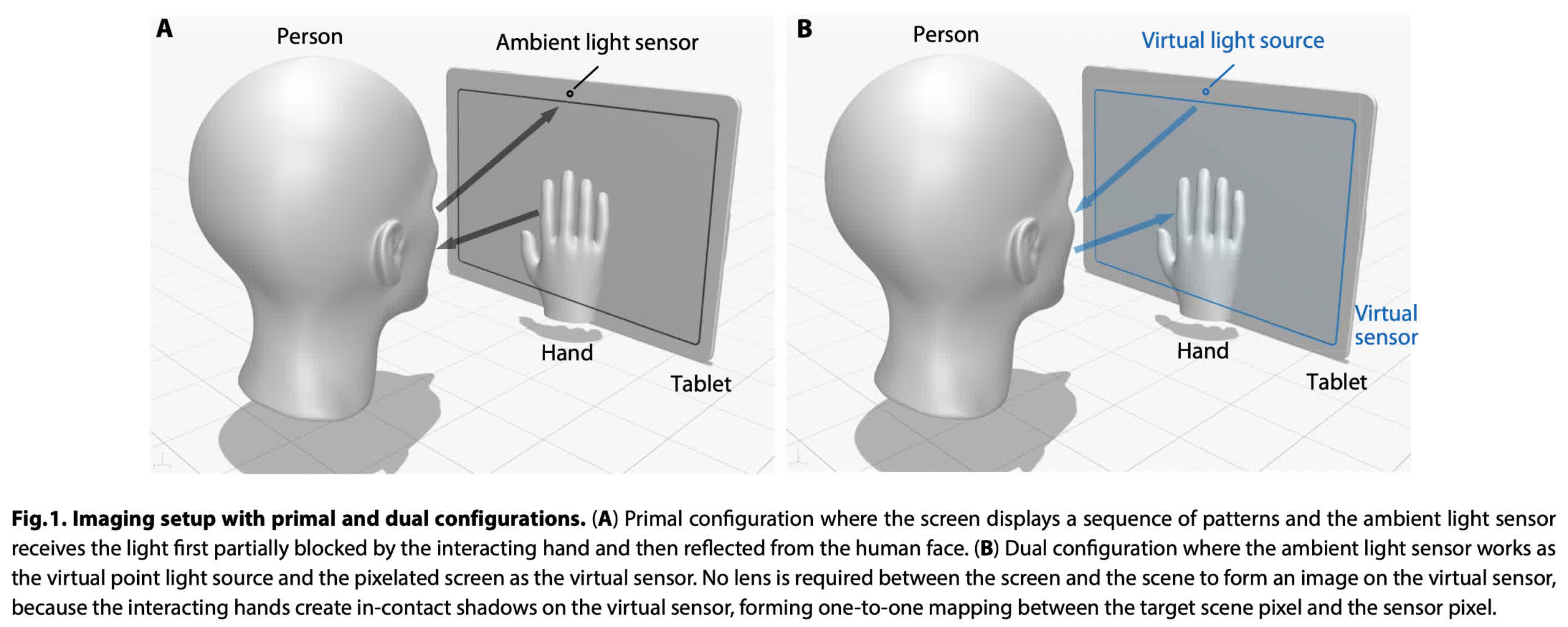
El proceso utiliza un principio físico llamado Reciprocidad de Helmholtz. Este concepto establece que las reflexiones, refracciones y absorciones experimentadas en la trayectoria de un rayo de luz son las mismas si el rayo tomó la misma ruta en sentido inverso. En pocas palabras, los algoritmos informáticos invierten los datos del sensor (inversión) para crear una imagen desde el punto de vista de la fuente de luz (pantalla), por ejemplo, una sombra sobre la pantalla.
Los investigadores lo demostraron utilizando una nueva tableta Samsung Galaxy View2 sin modificar con una pantalla de 17 pulgadas. Colocaron la tableta delante de una cabeza de maniquí y utilizaron recortes de cartón y manos humanas reales para simular gestos.
La iluminación tiene que ser específica para que el truco funcione de forma fiable. Recuerde, los algoritmos utilizan el trazado de ruta inversa desde el sensor hasta la fuente de luz, que es la pantalla. Entonces, los investigadores tuvieron que iluminar partes específicas de la pantalla para obtener una imagen legible. Dado que esto crearía un comportamiento muy inusual que un usuario podría considerar sospechoso, también replicaron el proceso utilizando una caricatura de Tom y Jerry modificada para lograr los patrones de iluminación adecuados.

Click para agrandar
Este método de fotografía dual creó imágenes de baja resolución (32×32) que eran lo suficientemente claras como para mostrar gestos como desplazarse con dos dedos o pellizcar con tres dedos. Debido a la resolución mínima, la técnica sólo funciona con pantallas más grandes, como tabletas y portátiles. Las pantallas de los teléfonos móviles son demasiado pequeñas.
Su mayor inconveniente es su velocidad. El sensor sólo puede grabar un píxel a la vez, por lo que se necesitan 1024 pasadas (menos de cinco por segundo) para crear una imagen de 32×32. En la práctica, esto significa que se necesitan 3,3 minutos para generar una imagen utilizando un patrón estático en blanco y negro. Usar el método de video modificado toma 68 minutos.
Afortunadamente para los consumidores, este nivel de lentitud es demasiado «incómodo» es un vector de ataque atractivo para los piratas informáticos. Esperar de tres minutos a una hora para procesar una imagen es demasiado ineficiente para que el método sea útil para algo más que una prueba de concepto. Los atacantes necesitarían un sensor exponencialmente más rápido para que este método pueda ser lo suficientemente viable como para obtener información beneficiosa.
«El tiempo de adquisición en minutos es demasiado engorroso para lanzar ataques simples y generales a la privacidad a escala masiva», dijo a IEEE Spectrum el investigador y consultor de seguridad independiente Lukasz Olejnik. «Sin embargo, no descartaría la importancia de las recogidas selectivas para operaciones adaptadas a los objetivos elegidos».
Aún así, sin una forma de capturar varias posiciones de las manos en corta sucesión, sería imposible obtener algo útil, como un PIN o una contraseña.



