Aurich Lawson | imágenes falsas
Con la mayoría de los programas informáticos, incluso los complejos, puedes rastrear meticulosamente el código y el uso de la memoria para determinar por qué ese programa genera cualquier comportamiento o resultado específico. En general, eso no es cierto en el campo de la IA generativa, donde las redes neuronales no interpretables que subyacen a estos modelos hacen que sea difícil incluso para los expertos determinar con precisión. por qué a menudo confabulan informaciónpor ejemplo.
Ahora, nueva investigación de Anthropic ofrece una nueva ventana a lo que sucede dentro de la «caja negra» de Claude LLM. De la empresa nuevo papel en «Extracción de características interpretables del soneto de Claude 3» describe un nuevo y poderoso método para explicar, al menos parcialmente, cómo se activan los millones de neuronas artificiales del modelo para crear respuestas sorprendentemente realistas a consultas generales.
abriendo el capó
Al analizar un LLM, es trivial ver qué neuronas artificiales específicas se activan en respuesta a una consulta en particular. Pero los LLM no se limitan a almacenar diferentes palabras o conceptos en una sola neurona. En cambio, como explican los investigadores de Anthropic, «resulta que cada concepto está representado a través de muchas neuronas, y cada neurona participa en la representación de muchos conceptos».
Para solucionar este lío de uno a muchos y de muchos a uno, se ha creado un sistema de codificadores automáticos escasos y se pueden usar matemáticas complicadas para ejecutar un algoritmo de «aprendizaje de diccionario» en todo el modelo. Este proceso resalta qué grupos de neuronas tienden a activarse de manera más consistente para las palabras específicas que aparecen en varias indicaciones de texto.

Estos patrones neuronales multidimensionales se clasifican luego en las llamadas «características» asociadas con determinadas palabras o conceptos. Estas características pueden abarcar cualquier cosa, desde simples nombres propios como el puente Golden Gate a conceptos más abstractos como errores de programación o la función de suma en código de computadora y a menudo representan el mismo concepto en múltiples idiomas y modos de comunicación (por ejemplo, texto e imágenes).
Un Octubre 2023 Estudio antrópico mostró cómo este proceso básico puede funcionar en modelos de juguetes extremadamente pequeños de una sola capa. El nuevo documento de la compañía amplía esto enormemente, identificando decenas de millones de características que están activas en su modelo Claude 3.0 Sonnet de tamaño mediano. El mapa de características resultante, que puede explorar parcialmente—crea «un mapa conceptual aproximado de [Claude’s] estados internos a mitad de su cálculo» y muestra «una profundidad, amplitud y abstracción que refleja las capacidades avanzadas de Sonnet», escriben los investigadores. Sin embargo, al mismo tiempo, los investigadores advierten que se trata de «una descripción incompleta de las representaciones internas del modelo». probablemente sea «órdenes de magnitud» más pequeños que un mapeo completo de Claude 3.
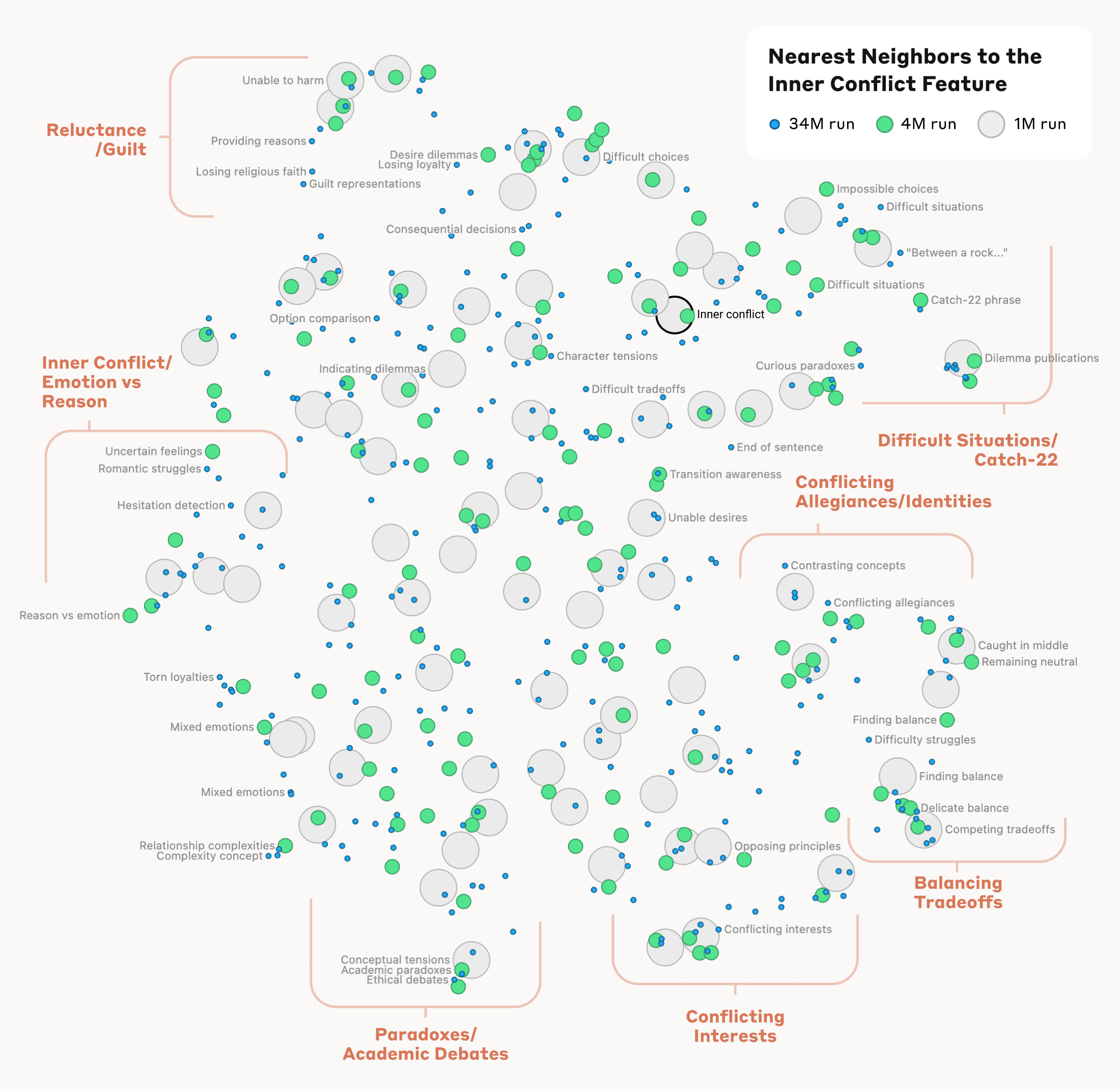
Incluso a nivel superficial, navegar por este mapa de características ayuda a mostrar cómo Claude vincula ciertas palabras clave, frases y conceptos en algo parecido al conocimiento. A característica etiquetada como «Capitales», por ejemplo, tiende a activarse fuertemente con las palabras «ciudad capital», pero también con nombres de ciudades específicas como Riga, Berlín, Azerbaiyán, Islamabad y Montpelier, Vermont, por nombrar sólo algunas.
El estudio también calcula una medida matemática de «distancia» entre diferentes características en función de su similitud neuronal. Los «vecindarios de características» resultantes encontrados por este proceso están «a menudo organizados en grupos geométricamente relacionados que comparten una relación semántica», escriben los investigadores, mostrando que «la organización interna de los conceptos en el modelo de IA corresponde, al menos en parte, a nuestra organización humana». nociones de semejanza.» La característica del puente Golden Gate, por ejemplo, es relativamente «cercana» a las características que describen «la isla de Alcatraz, la plaza Ghirardelli, los Golden State Warriors, el gobernador de California, Gavin Newsom, el terremoto de 1906 y la película de Alfred Hitchcock ambientada en San Francisco». Vértigo«.
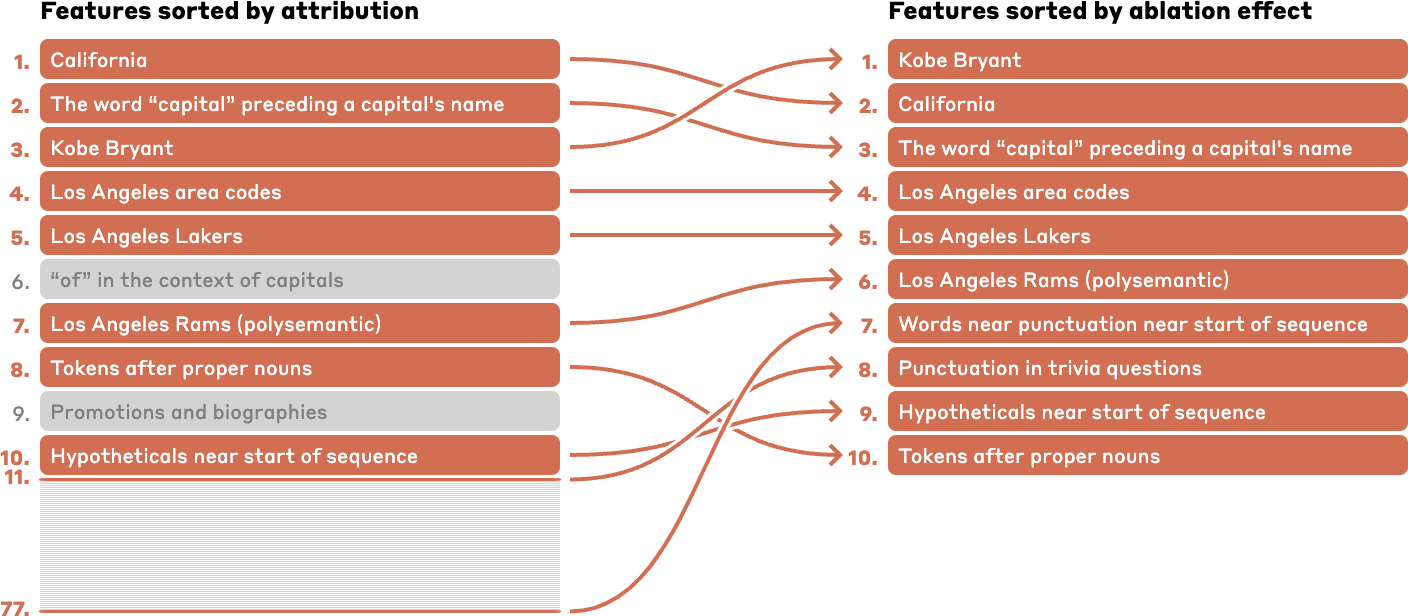
La identificación de características específicas del LLM también puede ayudar a los investigadores a trazar la cadena de inferencia que utiliza el modelo para responder preguntas complejas. Un mensaje sobre «La capital del estado donde Kobe Bryant jugó baloncesto», por ejemplo, muestra actividad en una cadena de artículos relacionados con «Kobe Bryant», «Los Angeles Lakers», «California», «Capitales» y «Sacramento». «, por nombrar algunos que se calculan para tener el mayor efecto en los resultados.