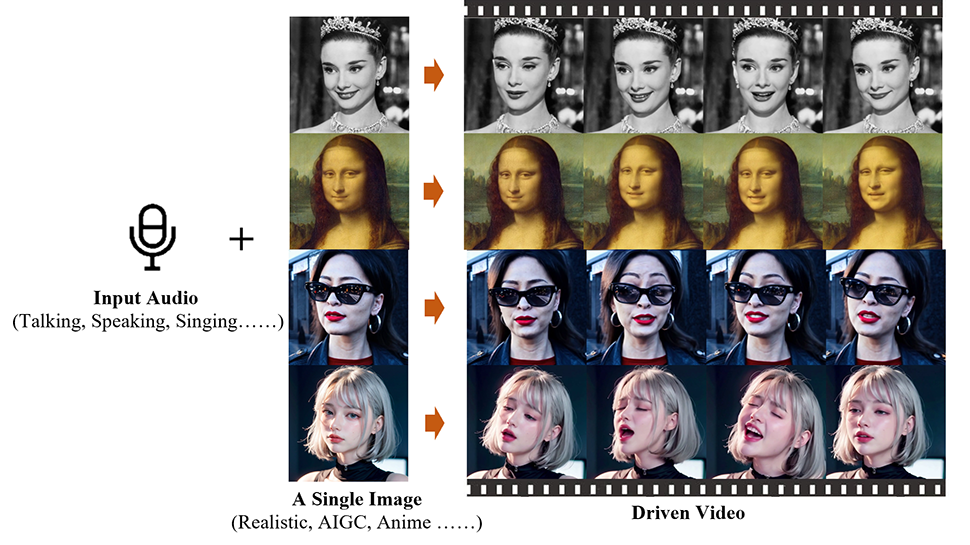
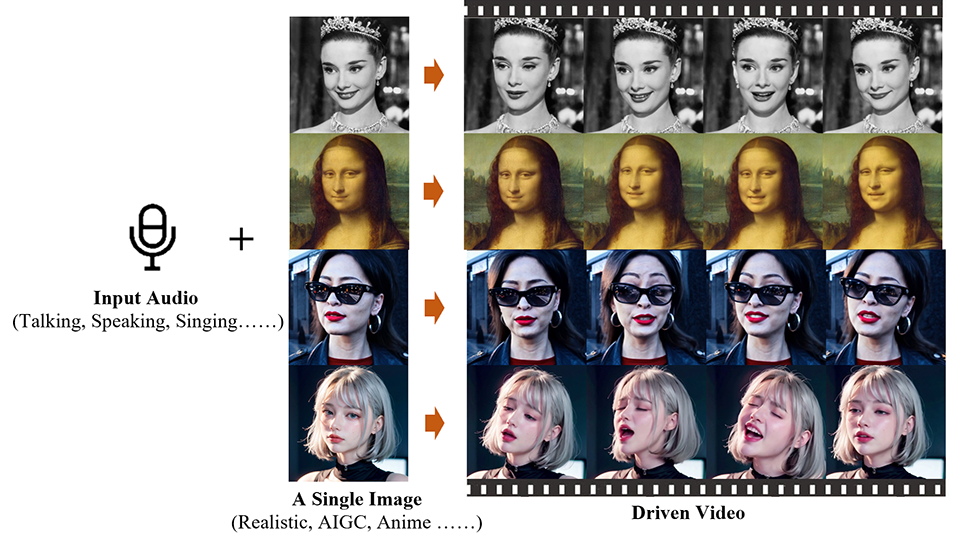
Ingenieros chinos del Instituto de Computación Inteligente del Grupo Alibaba han desarrollado una aplicación de inteligencia artificial llamada Emote Portrait Live que puede animar una fotografía fija de un rostro y sincronizarla con una pista de audio.
La tecnología detrás de esto se basa en las capacidades generativas de los modelos de difusión (modelos matemáticos utilizados para describir cómo las cosas se propagan o difunden a lo largo del tiempo), que pueden sintetizar directamente videos de cabezas de personajes a partir de una imagen proporcionada y cualquier clip de audio. Este proceso evita la necesidad de preprocesamiento complejo o representaciones intermedias, simplificando así la creación de vídeos de cabezas parlantes.
El desafío radica en capturar los matices y la diversidad de los movimientos faciales humanos durante la síntesis de video. Los métodos tradicionales simplifican esto imponiendo restricciones en la salida de video final, como el uso de modelos 3D para limitar los puntos clave faciales o la extracción de secuencias de movimientos de la cabeza de los videos base para guiar el movimiento general. Sin embargo, estas limitaciones pueden limitar la naturalidad y riqueza de las expresiones faciales resultantes.
No sin desafíos
El objetivo del equipo de investigación es desarrollar un marco de cabeza parlante que pueda capturar una amplia gama de expresiones faciales realistas, incluidas microexpresiones sutiles, y permitir movimientos naturales de la cabeza.
Sin embargo, la integración de audio con modelos de difusión presenta sus propios desafíos debido a la relación ambigua entre el audio y las expresiones faciales. Esto puede provocar inestabilidad en los vídeos producidos por el modelo, incluidas distorsiones faciales o fluctuaciones entre fotogramas de vídeo. Para superar esto, los investigadores incluyeron mecanismos de control estables en su modelo, específicamente un controlador de velocidad y un controlador de región frontal, para mejorar la estabilidad durante el proceso de generación.
A pesar del potencial de esta tecnología, existen ciertos inconvenientes. El proceso lleva más tiempo que los métodos que no utilizan modelos de difusión. Además, dado que no hay señales de control explícitas para guiar el movimiento del personaje, el modelo puede generar involuntariamente otras partes del cuerpo, como manos, lo que resulta en artefactos en el video.
el grupo tiene publicado un documento sobre su trabajo en el arXiv servidor de preimpresión y este sitio web es el hogar de una serie de otros videos que muestran las posibilidades de Emote Portrait Live, incluidos clips de Joaquin Phoenix (como The Joker), Leonardo DiCaprio y Audrey Hepburn.
Puedes ver a la Mona Lisa recitar el monólogo de Rosalind de la obra de Shakespeare. A su gustoActo 3, Escena 2, a continuación.