

El martes, Google anunció Lumièreun generador de video con IA al que llama «un modelo de difusión espacio-temporal para la generación de video realista» en el papel preimpreso adjunto. Pero no nos engañemos: hace un gran trabajo creando vídeos de animales lindos en escenarios ridículos, como patines, conduciendo un coche o tocando el piano. Claro, puede hacer más, pero es quizás el generador de video con IA de texto a animal más avanzado jamás demostrado.
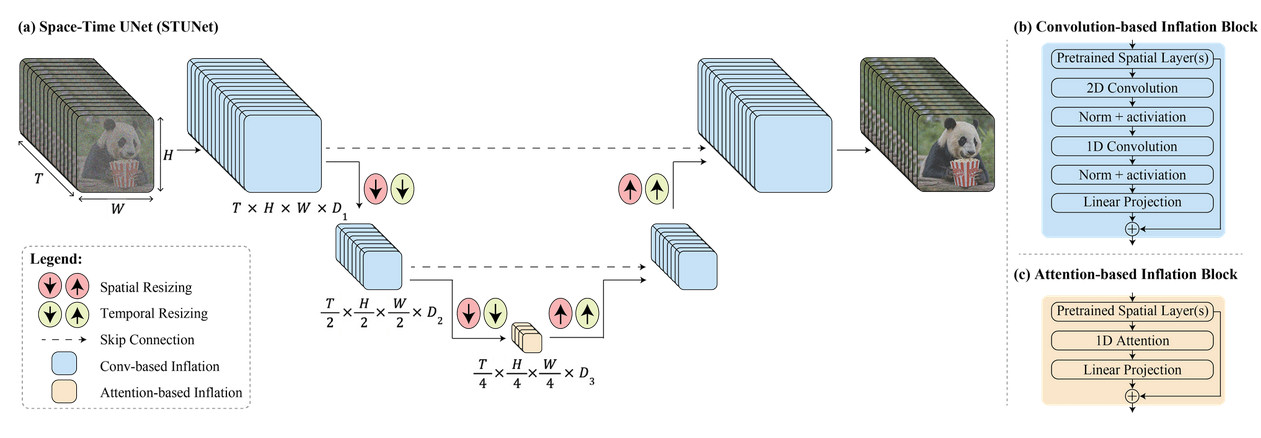
Según Google, Lumiere utiliza una arquitectura única para generar la duración temporal completa de un vídeo de una sola vez. O, como lo expresó la compañía, «Introducimos una arquitectura U-Net espacio-temporal que genera la duración temporal completa del video a la vez, a través de un solo paso en el modelo. Esto contrasta con los modelos de video existentes que sintetizan datos distantes». fotogramas clave seguidos de superresolución temporal, un enfoque que inherentemente hace que la coherencia temporal global sea difícil de lograr».
En términos simples, la tecnología de Google está diseñada para manejar los aspectos de espacio (dónde están las cosas en el video) y tiempo (cómo se mueven y cambian las cosas a lo largo del video) simultáneamente. Entonces, en lugar de hacer un video juntando muchas partes o fotogramas pequeños, puede crear el video completo, de principio a fin, en un proceso fluido.
El vídeo promocional oficial que acompaña al artículo «Lumiere: A Space-Time Diffusion Model for Video Generation», publicado por Google.
Lumiere también puede hacer muchos trucos de fiesta, que se explican bastante bien con ejemplos sobre Página de demostración de Google. Por ejemplo, puede generar texto a video (convertir un mensaje escrito en un video), convertir imágenes fijas en videos, generar videos en estilos específicos usando una imagen de referencia, aplicar una edición de video consistente usando mensajes basados en texto, crear cinemagrafías animando regiones específicas de una imagen y ofreciendo vídeo en pintura capacidades (por ejemplo, puede cambiar el tipo de vestimenta que lleva una persona).
En el artículo de investigación de Lumiere, los investigadores de Google afirman que el modelo de IA genera vídeos de 1024×1024 píxeles de cinco segundos de duración, que describen como de «baja resolución». A pesar de esas limitaciones, los investigadores realizaron un estudio de usuarios y afirman que los resultados de Lumiere fueron preferidos a los modelos de síntesis de video de IA existentes.
En cuanto a los datos de entrenamiento, Google no dice de dónde obtuvo los videos que introdujeron en Lumiere y escribe: «Entrenamos nuestro T2V [text to video] modelo en un conjunto de datos que contiene 30 millones de videos junto con su título de texto. [sic] Los videos tienen una duración de 80 fotogramas a 16 fps (5 segundos). El modelo base está entrenado a 128×128.»
El vídeo generado por IA todavía se encuentra en un estado primitivo, pero su calidad ha ido mejorando en los últimos dos años. En octubre de 2022, cubrimos el primer modelo de síntesis de imágenes presentado públicamente por Google. Imagen Video. Podía generar videoclips cortos de 1280 × 768 a partir de un mensaje escrito a 24 cuadros por segundo, pero los resultados no siempre fueron coherentes. Antes de eso, Meta estrenó su generador de video AI, Hacer un vídeo. En junio del año pasado, el modelo de síntesis de video Gen2 de Runway permitió la creación de videoclips de dos segundos a partir de indicaciones de texto, impulsando la creación de comerciales de parodia surrealista. Y en noviembre cubrimos Difusión de vídeo estableque puede generar clips cortos a partir de imágenes fijas.
Las empresas de inteligencia artificial a menudo hacen demostraciones de generadores de video con animales lindos porque generar humanos coherentes y no deformados es actualmente difícil, especialmente porque nosotros, como humanos (ustedes son humanos, ¿verdad?), somos expertos en notar cualquier defecto en los cuerpos humanos o en cómo se mueven. Basta con mirar los generados por IA Will Smith comiendo espaguetis.
A juzgar por los ejemplos de Google (y sin haberlo usado nosotros mismos), Lumiere parece superar estos otros modelos de generación de videos con IA. Pero dado que Google tiende a mantener sus modelos de investigación de IA en secreto, no estamos seguros de cuándo, si es que alguna vez, el público tendrá la oportunidad de probarlo por sí mismo.
Como siempre, cada vez que vemos que los modelos de síntesis de texto a video se vuelven más capaces, no podemos evitar pensar en implicaciones futuras para nuestra sociedad conectada a Internet, que se centra en compartir artefactos mediáticos, y la presunción general de que el vídeo «realista» normalmente representa objetos reales en situaciones reales captadas por una cámara. Las futuras herramientas de síntesis de vídeo más capaces que Lumiere harán que crear deepfakes engañosos sea trivialmente fácil.
Con ese fin, en la sección «Impacto social» del artículo de Lumiere, los investigadores escriben: «Nuestro objetivo principal en este trabajo es permitir a los usuarios novatos generar contenido visual de una manera creativa y flexible. [sic] Sin embargo, existe el riesgo de uso indebido al crear contenido falso o dañino con nuestra tecnología, y creemos que es crucial desarrollar y aplicar herramientas para detectar sesgos y casos de uso maliciosos con el fin de garantizar un uso seguro y justo».



{kind=link}