Los investigadores de AWS están trabajando en el desarrollo de un modelo de lenguaje grande-depurador basado en bases de datos en un esfuerzo por ayudar a las empresas a resolver problemas de rendimiento en dichos sistemas.
Apodado Panda, el nuevo marco de depuración ha sido diseñado para funcionar de una manera similar a un ingeniero de bases de datos (DBE), escribió la compañía en un entrada en el blogy agrega que solucionar problemas de rendimiento en una base de datos puede ser «notoriamente difícil».
A diferencia de los administradores de bases de datos, que tienen la tarea de administrar múltiples bases de datos, los ingenieros de bases de datos tienen la tarea de diseñar, desarrollar y mantener bases de datos.
Panda, efectivamente, es un marco que proporciona una base contextual a los LLM previamente capacitados para generar recomendaciones de solución de problemas más «útiles» y «en contexto», explicaron los investigadores.
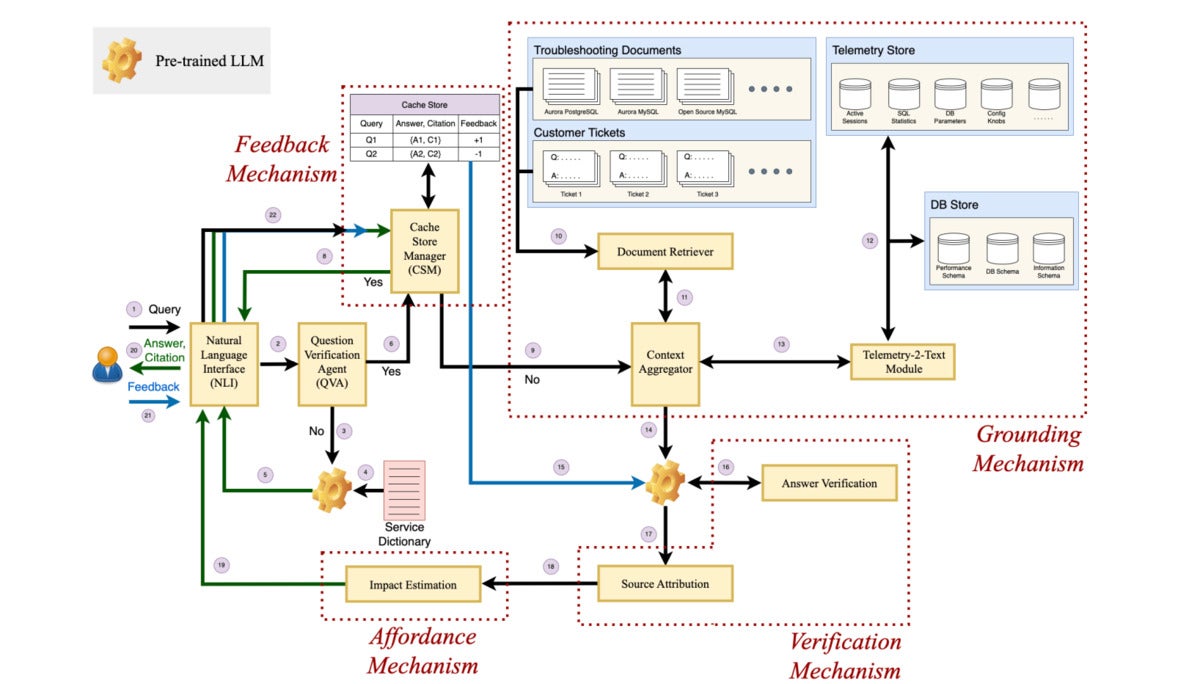
Componentes y arquitectura de Panda.
El marco incluye cuatro componentes clave, toma de tierraverificación, asequibilidad y retroalimentación.
Los investigadores describen la verificación como la capacidad del modelo para poder verificar la respuesta generada utilizando fuentes relevantes y producir la cita junto con su resultado para que el usuario final pueda verificarla.
Por otro lado, la asequibilidad puede describirse como la capacidad del marco para informar al usuario sobre las consecuencias de la acción recomendada sugerida por un LLM mientras resalta explícitamente las acciones de alto riesgo, como DROP o DELETE, dijeron los investigadores.
El componente de retroalimentación de Panda, según los investigadores, permite que el depurador basado en LLM acepte comentarios del usuario y los tenga en cuenta al generar respuestas.
Estos cuatro componentes, a su vez, conforman la arquitectura del depurador, que incluye el agente de verificación de preguntas (QVA), el mecanismo de conexión a tierra, el mecanismo de verificación, el mecanismo de retroalimentación y el mecanismo de prestación.
Mientras que QVA identifica y filtra las consultas irrelevantes, el mecanismo de conexión a tierra comprende un recuperador de documentos, Telemetría-2-texto y un agregador de contexto para proporcionar más contexto a un mensaje o consulta.
El mecanismo de verificación comprende la verificación de la respuesta y la atribución de la fuente, dijeron los investigadores, y agregaron que todos estos mecanismos junto con el mecanismo de retroalimentación y prestación funcionan en el fondo de una interfaz de lenguaje natural (NL) con la que interactúa el usuario empresarial.
Lanzando Panda contra GPT-4 de OpenAI
Los investigadores que trabajan en AWS también enfrentaron a Panda contra el modelo GPT-4 de OpenAI, que actualmente subraya ChatGPT.
«… solicitar a ChatGPT consultas sobre el rendimiento de la base de datos a menudo da como resultado recomendaciones ‘técnicamente correctas’ pero muy ‘vagas’ o ‘genéricas’ que los ingenieros de bases de datos experimentados (DBE) suelen considerar inútiles y poco confiables», afirman los investigadores. escribió mientras muestra un resultado al solucionar problemas de una Aurora PostgreSQL base de datos.
Para el experimento, los investigadores de AWS habían reunido un grupo de DBE con tres niveles de competencia diferentes y la mayoría de ellos se inclinaron a favor de Panda, según muestra el documento.
Además, los investigadores afirmaron que Panda, aunque se utilizó en bases de datos en la nube en su experimento, se puede extender a cualquier sistema de base de datos.
Copyright © 2024 IDG Communications, Inc.




