El artículo, Aprendizaje automático para desarrolladores de Java: algoritmos para el aprendizaje automático, presentó la configuración de un algoritmo de aprendizaje automático y el desarrollo de una función de predicción en Java. Los lectores aprendieron el funcionamiento interno de un algoritmo de aprendizaje automático y recorrieron el proceso de desarrollo y entrenamiento de un modelo. Este artículo continúa donde lo dejó. Obtendrá una introducción rápida a Weka, un marco de aprendizaje automático para Java. Luego, verá cómo configurar una canalización de datos de aprendizaje automático, con un proceso paso a paso para llevar su modelo de aprendizaje automático desde el desarrollo a la producción. También discutiremos brevemente cómo usar contenedores Docker y REST para implementar un modelo de ML entrenado en un entorno de producción basado en Java.
Qué esperar de este artículo
Implementar un modelo de aprendizaje automático no es lo mismo que desarrollar uno. Estas son diferentes partes del ciclo de vida del desarrollo de software y, a menudo, las implementan diferentes equipos. Desarrollar un modelo de aprendizaje automático requiere comprender los datos subyacentes y tener buenos conocimientos de matemáticas y estadística. La implementación de un modelo de aprendizaje automático en producción suele ser un trabajo para alguien con experiencia en ingeniería de software y operaciones.
Este artículo trata sobre cómo hacer que un modelo de aprendizaje automático esté disponible en un entorno de producción altamente escalable. Se supone que tiene cierta experiencia en desarrollo y conocimientos básicos de modelos y algoritmos de aprendizaje automático; de lo contrario, es posible que desees comenzar leyendo Aprendizaje automático para desarrolladores de Java: algoritmos para el aprendizaje automático.
Comencemos con un repaso rápido sobre el aprendizaje supervisado, incluida la aplicación de ejemplo que usaremos para entrenar, implementar y procesar un modelo de aprendizaje automático para su uso en producción.
Aprendizaje automático supervisado: un repaso
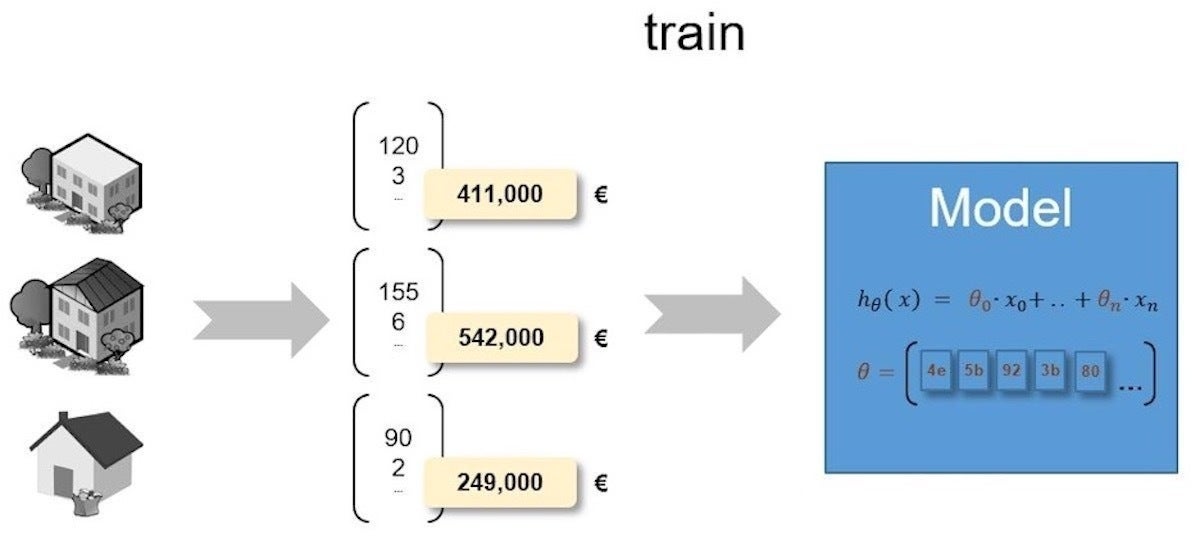
Un modelo de aprendizaje automático simple y supervisado ilustrará el proceso de implementación de ML. El modelo que se muestra en la Figura 1 se puede utilizar para predecir el precio de venta esperado de una casa.
 IDG
IDGFigura 1. Modelo de aprendizaje automático supervisado y capacitado para la predicción de precios de venta.
Recuerde que un modelo de aprendizaje automático es una función con parámetros internos que se pueden aprender y que asignan entradas a salidas. En el diagrama anterior, una función de regresión lineal, hi(X), se utiliza para predecir el precio de venta de una casa en función de una variedad de características. El X Las variables de la función representan los datos de entrada. El i Las variables (theta) representan los parámetros internos del modelo que se pueden aprender.
Para predecir el precio de venta de una casa, primero debe crear una matriz de datos de entrada de X variables. Esta matriz contiene características como el tamaño del lote o el número de habitaciones de una casa. Esta matriz se llama vector de caracteristicas.
Debido a que la mayoría de las funciones de aprendizaje automático requieren una representación numérica de las características, es probable que deba realizar algunas transformaciones de datos para crear un vector de características. Por ejemplo, una característica que especifique la ubicación del garaje podría incluir etiquetas como «adjunto a la casa» o «integrado», que deben asignarse a valores numéricos. Cuando ejecute la predicción del precio de la vivienda, la función de aprendizaje automático se aplicará con este vector de características de entrada, así como con los parámetros internos del modelo entrenado. El resultado de la función es el precio estimado de la vivienda. Esta salida se llama etiqueta.
Entrenando el modelo
Los parámetros internos del modelo que se pueden aprender (θ) son la parte del modelo que se aprende a partir de los datos de entrenamiento. Los parámetros que se pueden aprender se establecerán durante el proceso de capacitación. Es necesario entrenar un modelo de aprendizaje automático supervisado como el que se muestra a continuación para poder realizar predicciones útiles.
 IDG
IDGFigura 2. Un modelo de aprendizaje automático supervisado no capacitado
Normalmente, el proceso de entrenamiento comienza con un modelo no entrenado donde todos los parámetros que se pueden aprender se establecen con un valor inicial como cero. El modelo consume datos sobre varias características de la casa junto con los precios reales de la misma. Poco a poco, identifica correlaciones entre las características de la vivienda y los precios de la vivienda, así como el peso de estas relaciones. El modelo ajusta sus parámetros internos que se pueden aprender y los utiliza para hacer predicciones.
 IDG
IDGFigura 3. Un modelo de aprendizaje automático supervisado y entrenado
Tras el proceso de formación, el modelo será capaz de estimar el precio de venta de una casa valorando sus características.
Algoritmos de aprendizaje automático en código Java
El HousePriceModel proporciona dos métodos. Uno de ellos implementa el algoritmo de aprendizaje para entrenar (o adaptar) el modelo. El otro método se utiliza para las predicciones.
 IDG
IDGFigura 4. Dos métodos en un modelo de aprendizaje automático
El método de ajuste()
El fit() El método se utiliza para entrenar el modelo. Consume las características de la casa y los precios de venta de la misma como parámetros de entrada, pero no devuelve nada. Este método requiere la «respuesta» correcta para poder ajustar los parámetros internos del modelo. Utilizando listados de viviendas combinados con precios de venta, el algoritmo de aprendizaje busca patrones en los datos de entrenamiento. A partir de estos, produce parámetros de modelo que se generalizan a partir de esos patrones. A medida que los datos de entrada se vuelven más precisos, se ajustan los parámetros internos del modelo.
Listado 1. El método fit() se utiliza para entrenar un modelo de aprendizaje automático
// load training data
// ...
// e.g. [{MSSubClass=60.0, LotFrontage=65.0, ...}, {MSSubClass=20.0, ...}]
List<Map<String, Double>> houses = ...;
// e.g. [208500.0, 181500.0, 223500.0, 140000.0, 250000.0, ...]
List<Double> prices = ...;
// create and train the model
var model = new HousePriceModel();
model.fit(houses, prices);
Tenga en cuenta que las características de la casa se escriben dos veces en el código. Esto se debe a que el algoritmo de aprendizaje automático utilizado para implementar el método fit() requiere números como entrada. Todas las características de la casa deben representarse numéricamente para que puedan usarse como X parámetros en la fórmula de regresión lineal, como se muestra aquí:
hθ(x) = θ0 * x0 + ... + θn * xn
El modelo de predicción del precio de la vivienda entrenado podría verse como lo que se ve a continuación:
price = -490130.8527 * 1 + -241.0244 * MSSubClass + -143.716 * LotFrontage + … * …
Aquí, la casa de entrada presenta características como MSSubClass o LotFrontage están representados como X variables. Los parámetros del modelo que se pueden aprender (θ) se establecen con valores como -490130.8527 o -241.0244, que se obtuvieron durante el proceso de capacitación.
Este ejemplo utiliza un algoritmo de aprendizaje automático simple, que requiere solo unos pocos parámetros del modelo. Un algoritmo más complejo, como por ejemplo para un red neuronal profunda, podría requerir millones de parámetros del modelo; Ésta es una de las principales razones por las que el proceso de entrenamiento de dichos algoritmos requiere una alta potencia de cálculo.
El método predecir()
Una vez que haya terminado de entrenar el modelo, puede utilizar el predict() Método para determinar el precio de venta estimado de una casa. Este método consume datos sobre las características de la casa y produce un precio de venta estimado. En la práctica, un agente de una empresa inmobiliaria podría introducir características como el tamaño del lote (lot-area), el número de habitaciones o la calidad general de la casa para recibir un precio de venta estimado para una casa determinada.
Transformar valores no numéricos
A menudo se encontrará con conjuntos de datos que contienen valores no numéricos. Por ejemplo, el Conjunto de datos de vivienda de Ames utilizado para el Precios de las casas en Kaggle El concurso incluye listados numéricos y textuales de las características de la casa:
 IDG
IDGFigura 5. Una muestra del conjunto de datos de Kaggle House Prices
Para complicar más las cosas, el conjunto de datos de Kaggle también incluye valores vacíos (marcados NA), que no pueden ser procesados por el algoritmo de regresión lineal que se muestra en el Listado 1.
Los registros de datos del mundo real suelen ser incompletos, inconsistentes, carentes de comportamientos o tendencias deseados y pueden contener errores. Esto suele ocurrir en casos en los que los datos de entrada se han unido utilizando diferentes fuentes. Los datos de entrada deben convertirse en un conjunto de datos limpio antes de introducirlos en un modelo.
Para mejorar los datos, deberá reemplazar el número (NA) que falta LotFrontage valor. También necesitaría reemplazar valores textuales como MSZoning «RL» o «RM» con valores numéricos. Estas transformaciones son necesarias para convertir los datos sin procesar a un formato sintácticamente correcto que pueda ser procesado por su modelo.
Una vez que haya convertido sus datos a un formato generalmente legible, es posible que aún necesite realizar cambios adicionales para mejorar la calidad de los datos de entrada. Por ejemplo, puede eliminar valores que no sigan la tendencia general de los datos o colocar categorías que aparecen con poca frecuencia en una única categoría general.
Aprendizaje automático basado en Java con Weka
Como ha visto, desarrollar y probar una función de destino requiere parámetros de configuración bien ajustados, como la tasa de aprendizaje adecuada o el recuento de iteraciones. El código de ejemplo que ha visto hasta ahora refleja un conjunto muy pequeño de posibles parámetros de configuración y los ejemplos se simplificaron para mantener el código legible. En la práctica, es probable que dependa de marcos, bibliotecas y herramientas de aprendizaje automático.
La mayoría de los marcos o bibliotecas implementan una extensa colección de algoritmos de aprendizaje automático. Además, proporcionan API convenientes de alto nivel para entrenar, validar y procesar modelos de datos. Weka es uno de los frameworks más populares para JVM.
Weka proporciona una biblioteca Java para uso programático, así como un banco de trabajo gráfico para entrenar y validar modelos de datos. En el código siguiente, se utiliza la biblioteca Weka para crear un conjunto de datos de entrenamiento, que incluye características y una etiqueta. El setClassIndex() El método se utiliza para marcar la columna de etiqueta. En Weka, la etiqueta se define como una clase:
// define the feature and label attributes
ArrayList<Attribute> attributes = new ArrayList<>();
Attribute sizeAttribute = new Attribute("sizeFeature");
attributes.add(sizeAttribute);
Attribute squaredSizeAttribute = new Attribute("squaredSizeFeature");
attributes.add(squaredSizeAttribute);
Attribute priceAttribute = new Attribute("priceLabel");
attributes.add(priceAttribute);
// create and fill the features list with 5000 examples
Instances trainingDataset = new Instances("trainData", attributes, 5000);
trainingDataset.setClassIndex(trainingSet.numAttributes() - 1);
Instance instance = new DenseInstance(3);
instance.setValue(sizeAttribute, 90.0);
instance.setValue(squaredSizeAttribute, Math.pow(90.0, 2));
instance.setValue(priceAttribute, 249.0);
trainingDataset.add(instance);
Instance instance = new DenseInstance(3);
instance.setValue(sizeAttribute, 101.0);
...
El conjunto de datos o Instance El objeto también se puede almacenar y cargar como un archivo. Weka utiliza un ARFF (Formato de archivo de relación de atributos), que es compatible con el banco de trabajo gráfico Weka. Este conjunto de datos se utiliza para entrenar la función objetivo, conocida como clasificador en Weka.
Recuerde que para entrenar una función objetivo, primero debe elegir el algoritmo de aprendizaje automático. El siguiente código crea una instancia de LinearRegression clasificador. Este clasificador se entrena llamando al buildClassifier() método. El buildClassifier() El método ajusta los parámetros theta en función de los datos de entrenamiento para encontrar el modelo que mejor se ajuste. Con Weka, no tiene que preocuparse por establecer una tasa de aprendizaje o un recuento de iteraciones. Weka también escala la función internamente:
Classifier targetFunction = new LinearRegression();
targetFunction.buildClassifier(trainingDataset);
Una vez establecida, la función objetivo se puede utilizar para predecir el precio de una casa, como se muestra aquí:
Instances unlabeledInstances = new Instances("predictionset", attributes, 1);
unlabeledInstances.setClassIndex(trainingSet.numAttributes() - 1);
Instance unlabeled = new DenseInstance(3);
unlabeled.setValue(sizeAttribute, 1330.0);
unlabeled.setValue(squaredSizeAttribute, Math.pow(1330.0, 2));
unlabeledInstances.add(unlabeled);
double prediction = targetFunction.classifyInstance(unlabeledInstances.get(0));
Weka proporciona una Evaluation clase para validar el clasificador o modelo entrenado. En el código siguiente, se utiliza un conjunto de datos de validación dedicado para evitar resultados sesgados. Medidas como el costo o la tasa de error se imprimirán en la consola. Normalmente, los resultados de la evaluación se utilizan para comparar modelos que han sido entrenados utilizando diferentes algoritmos de aprendizaje automático, o una variante de estos:
Evaluation evaluation = new Evaluation(trainingDataset);
evaluation.evaluateModel(targetFunction, validationDataset);
System.out.println(evaluation.toSummaryString("Results", false));
Los ejemplos anteriores utilizan la regresión lineal, que predice un resultado con valor numérico, como el precio de una vivienda, en función de los valores de entrada. La regresión lineal admite la predicción de valores numéricos continuos. Para predecir valores o clasificadores binarios de sí/no, puede utilizar un algoritmo de aprendizaje automático como árbol de decisión, red neuronal o regresión logística:
// using logistic regression
Classifier targetFunction = new Logistic();
targetFunction.buildClassifier(trainingSet);