
Grandes modelos de lenguaje como ChatGPT y Bardo han levantado aprendizaje automático al estatus de un fenómeno. Su utilizar para asistencia de codificación rápidamente le ha ganado a estas herramientas un lugar en el kit de herramientas del desarrollador. Se están explorando otros casos de uso, que van desde la generación de imágenes hasta la detección de enfermedades.
Las empresas tecnológicas están invirtiendo mucho en aprendizaje automático, por lo que saber cómo entrenar y trabajar con modelos se está volviendo esencial para los desarrolladores.
Este artículo le permitirá empezar a utilizar el aprendizaje automático en Java. Obtendrá un primer vistazo a cómo funciona el aprendizaje automático, seguido de una breve guía para implementar y entrenar un algoritmo de aprendizaje automático. Nos centraremos en aprendizaje automático supervisadoque es el enfoque más común para desarrollar aplicaciones inteligentes.
Aprendizaje automático e IA
El aprendizaje automático ha evolucionado desde el campo de inteligencia artificial (IA), que busca producir máquinas capaces de imitar la inteligencia humana. Aunque el aprendizaje automático es una tendencia candente en la informática, la IA no es un campo nuevo en la ciencia. El Prueba de Turing, desarrollada por Alan Turing a principios de los años 50, fue una de las primeras pruebas creadas para determinar si una computadora podría tener inteligencia real. Según la prueba de Turing, una computadora podría demostrar la inteligencia humana engañando a un humano haciéndole creer que también era humano.
Muchos enfoques de aprendizaje automático de última generación se basan en conceptos que tienen décadas de antigüedad. Lo que ha cambiado en la última década es que las computadoras (y las plataformas informáticas distribuidas) ahora tienen la potencia de procesamiento necesaria para los algoritmos de aprendizaje automático. La mayoría de los algoritmos de aprendizaje automático exigen una gran cantidad de multiplicaciones de matrices y otras operaciones matemáticas para procesar. La tecnología computacional para gestionar estos cálculos no existía ni siquiera hace dos décadas, pero sí existe hoy. El procesamiento paralelo y los chips dedicados, así como el big data, han aumentado radicalmente la capacidad de las plataformas de aprendizaje automático.
El aprendizaje automático permite a los programas ejecutar procesos de mejora de la calidad y ampliar sus capacidades sin participación humana. Algunos programas creados con aprendizaje automático son incluso capaces de actualizar o ampliar su propio código.
Cómo aprenden las máquinas
El aprendizaje supervisado y el aprendizaje no supervisado son los enfoques más populares del aprendizaje automático. Ambos requieren alimentar a la máquina con una gran cantidad de registros de datos para correlacionarlos y aprender de ellos. Estos registros de datos recopilados se conocen comúnmente como vectores de caracteristicas. En el caso de una casa individual, un vector de características podría consistir en características como el tamaño total de la casa, el número de habitaciones y la antigüedad de la casa.
Aprendizaje supervisado
En aprendizaje supervisado, se entrena un algoritmo de aprendizaje automático para responder correctamente a preguntas relacionadas con vectores de características. Para entrenar un algoritmo, la máquina recibe un conjunto de vectores de características y una etiqueta asociada. Las etiquetas suelen ser proporcionadas por un anotador humano y representan la respuesta correcta a una pregunta determinada. El algoritmo de aprendizaje analiza vectores de características y sus etiquetas correctas para encontrar estructuras internas y relaciones entre ellos. Así, la máquina aprende a responder correctamente a las consultas.
Por ejemplo, una aplicación inmobiliaria inteligente podría entrenarse con vectores de características que incluyan el tamaño, la cantidad de habitaciones y la antigüedad respectivos de una variedad de casas. Un etiquetador humano etiquetaría cada casa con el precio correcto en función de estos factores. Al analizar los datos, la aplicación de bienes raíces estaría entrenada para responder la pregunta: «¿Cuánto dinero podría obtener por esta casa?»
Una vez finalizado el proceso de formación, los nuevos datos de entrada no se etiquetan. La máquina es capaz de responder correctamente a nuevas consultas, incluso para vectores de características invisibles y sin etiquetar.
Aprendizaje sin supervisión
En aprendizaje sin supervisión, el algoritmo está programado para predecir respuestas sin etiquetado humano, ni siquiera preguntas. En lugar de predeterminar etiquetas o cuáles deberían ser los resultados, el aprendizaje no supervisado aprovecha conjuntos de datos masivos y potencia de procesamiento para descubrir correlaciones previamente desconocidas. En el marketing de productos de consumo, por ejemplo, el aprendizaje no supervisado podría utilizarse para identificar relaciones ocultas o agrupaciones de consumidores, lo que eventualmente conduciría a estrategias de marketing nuevas o mejoradas.
Este artículo se centra en el aprendizaje automático supervisado, que actualmente es el enfoque más común de aprendizaje automático.
Un proyecto supervisado de aprendizaje automático
Ahora veamos un ejemplo: un proyecto de aprendizaje supervisado para una aplicación inmobiliaria.
Todo el aprendizaje automático se basa en datos. Básicamente, ingresas muchas instancias de datos y los resultados del mundo real de esos datos, y el algoritmo forma un modelo matemático basado en esas entradas. Con el tiempo, la máquina aprende a utilizar nuevos datos para predecir resultados desconocidos.
Para un proyecto de aprendizaje automático supervisado, deberá etiquetar los datos de manera significativa para el resultado que busca. En la Tabla 1, observe que cada fila del registro de la vivienda incluye una etiqueta para «precio de la vivienda». Al correlacionar los datos de la fila con la etiqueta del precio de la vivienda, el algoritmo eventualmente podrá predecir el precio de mercado de una casa que no está en su conjunto de datos (tenga en cuenta que el tamaño de la casa se basa en metros cuadrados y el precio de la casa en euros).
Tabla 1. Registros de la casa
| CARACTERÍSTICA | CARACTERÍSTICA | CARACTERÍSTICA | ETIQUETA |
| Tamaño de la casa | Número de habitaciones | Edad de la casa | Costo estimado |
|
90 metros2 / 295 pies |
2 | 23 años |
249.000€ |
|
101 metros2 / 331 pies |
3 | N / A |
338.000€ |
|
1330 m2 / 4363 pies |
11 | 12 años |
6.500.000€ |
En las primeras etapas, probablemente etiquetará los registros de datos a mano, pero eventualmente podría entrenar su programa para automatizar este proceso. Probablemente hayas visto esto con aplicaciones de correo electrónico, donde al mover el correo electrónico a tu carpeta de spam aparece la pregunta «¿Es esto spam?» Cuando responde, está entrenando al programa para que reconozca el correo que no desea ver. El filtro de spam de la aplicación aprende a etiquetar y eliminar correo futuro de la misma fuente o que contenga contenido similar.
Los conjuntos de datos etiquetados solo son necesarios con fines de capacitación y prueba. Una vez finalizada esta fase, el modelo de aprendizaje automático funciona en instancias de datos sin etiquetar. Por ejemplo, podría alimentar al algoritmo de predicción con un nuevo registro de casa sin etiquetar y automáticamente predeciría el precio esperado de la casa en función de los datos de entrenamiento.
Entrenando un modelo de aprendizaje automático
El desafío del aprendizaje automático supervisado es encontrar la función de predicción adecuada para una pregunta específica. Matemáticamente, el desafío es encontrar la función de entrada/salida que toma la variable de entrada X y devuelve el valor de predicción y. Este función de hipótesis (hi) es el resultado del proceso de formación. A menudo, la función de hipótesis también se llama objetivo o predicción función.
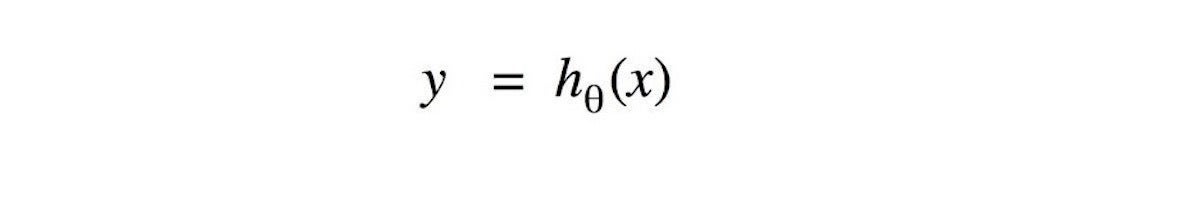 Gregorio Roth
Gregorio RothFigura 1. Ejemplo de una función objetivo
En la mayoría de los casos, X representa un punto de datos múltiples. En nuestro ejemplo, este podría ser un punto de datos bidimensional de una casa individual definida por el tamaño de la casa valor y el número de habitaciones valor. La matriz de estos valores se conoce como vector de caracteristicas. Dada una función objetivo concreta, la función se puede utilizar para hacer una predicción para cada vector de características, X. Para predecir el precio de una casa individual, puede llamar a la función objetivo utilizando el vector de características {101,0, 3,0}que contiene el tamaño de la casa y el número de habitaciones:
Listado 1. Llamar a la función objetivo con un vector de características
// target function h (which is the output of the learn process)
Function<Double[], Double> h = ...;
// set the feature vector with house size=101 and number-of-rooms=3
Double[] x = new Double[] { 101.0, 3.0 };
// and predicted the house price (label)
double y = h.apply(x);
En el Listado 1, la variable de matriz X El valor representa el vector de características de la casa. El y El valor devuelto por la función objetivo es el precio previsto de la vivienda.
El desafío del aprendizaje automático es definir una función objetivo que funcione con la mayor precisión posible para instancias de datos desconocidas e invisibles. En el aprendizaje automático, la función objetivo (hi) a veces se le llama modelo. Este modelo es el resultado del proceso de aprendizaje, también llamado entrenamiento modelo.
 Gregorio Roth
Gregorio RothFigura 2. Un modelo de aprendizaje automático
Basado en ejemplos de entrenamiento etiquetados, el algoritmo de aprendizaje busca estructuras o patrones en los datos de entrenamiento. Lo hace con un proceso conocido como propagación hacia atrás, donde los valores se modifican gradualmente para reducir la pérdida. A partir de estos, produce un modelo que es capaz de generalizar a partir de esos datos.
Generalmente el proceso de aprendizaje es exploratorio. En la mayoría de los casos, el proceso se ejecutará varias veces utilizando diferentes variaciones de configuraciones y algoritmos de aprendizaje. Cuando se decide un modelo, los datos también se analizan en él muchas veces. Estas iteraciones se conocen como épocas.
Finalmente, todos los modelos se evaluarán en función de métricas de rendimiento. Se seleccionará el mejor y se utilizará para calcular predicciones para futuras instancias de datos sin etiquetar.
Regresión lineal
Para entrenar una máquina para que piense, el primer paso es elegir el algoritmo de aprendizaje que utilizará. Regresión lineal es uno de los algoritmos de aprendizaje supervisado más simples y populares. Este algoritmo supone que la relación entre las características de entrada y la etiqueta de salida es lineal. La función de regresión lineal genérica en la Figura 3 devuelve el valor predicho al resumir cada elemento de la vector de caracteristicas multiplicado por un parámetro theta (θ). Los parámetros theta se utilizan dentro del proceso de entrenamiento para adaptar o «ajustar» la función de regresión en función de los datos de entrenamiento.
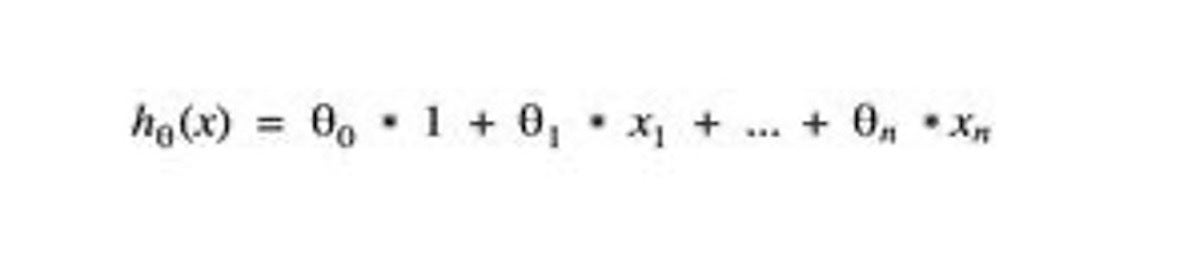 Gregorio Roth
Gregorio RothFigura 3. Una función de regresión lineal genérica
La regresión lineal es un tipo simple de función de aprendizaje, pero proporciona una buena base para formas más avanzadas como el descenso de gradiente, que se utiliza en redes neuronales de alimentación directa. En la función de regresión lineal, los parámetros theta y los parámetros de características se enumeran mediante un número de suscripción. El número de suscripción indica la posición de los parámetros theta (θ) y los parámetros de característica (x) dentro del vector. Tenga en cuenta que la característica x0 es un término de compensación constante establecido con el valor 1 con fines computacionales. Como resultado, el índice de una característica específica de un dominio, como el tamaño de la casa, comenzará con x1. Entonces, si x1 se establece para el primer valor del vector de características de la casa, tamaño de la casa, luego x2 se establecerá para el siguiente valor, número de habitaciones, etc.
El Listado 2 muestra una implementación Java de esta función de regresión lineal, mostrada matemáticamente como hi(X). Para simplificar, el cálculo se realiza utilizando el tipo de datos double. Dentro de apply() método, se espera que el primer elemento de la matriz se haya establecido con un valor de 1,0 fuera de esta función.
Listado 2. Regresión lineal en Java
public class LinearRegressionFunction implements Function<Double[], Double> {
private final double[] thetaVector;
LinearRegressionFunction(double[] thetaVector) {
this.thetaVector = Arrays.copyOf(thetaVector, thetaVector.length);
}
public Double apply(Double[] featureVector) {
// for computational reasons the first element has to be 1.0
assert featureVector[0] == 1.0;
// simple, sequential implementation
double prediction = 0;
for (int j = 0; j < thetaVector.length; j++) {
prediction += thetaVector[j] * featureVector[j];
}
return prediction;
}
public double[] getThetas() {
return Arrays.copyOf(thetaVector, thetaVector.length);
}
}
Para crear una nueva instancia del LinearRegressionFunction, debe configurar el parámetro theta. El parámetro theta, o vector, se utiliza para adaptar la función de regresión genérica a los datos de entrenamiento subyacentes. Los parámetros theta del programa se ajustarán durante el proceso de aprendizaje, basándose en ejemplos de capacitación. La calidad de la función objetivo entrenada solo puede ser tan buena como la calidad de los datos de entrenamiento proporcionados.
En el siguiente ejemplo, el LinearRegressionFunction Se creará una instancia para predecir el precio de la casa en función del tamaño de la casa. considerando que x0 tiene que ser un valor constante de 1,0, la función objetivo se crea una instancia utilizando dos parámetros theta. Los parámetros theta son el resultado de un proceso de aprendizaje. Después de crear la nueva instancia, el precio de una casa con un tamaño de 1330 metros cuadrados se predecirá de la siguiente manera:
// the theta vector used here was output of a train process
double[] thetaVector = new double[] { 1.004579, 5.286822 };
LinearRegressionFunction targetFunction = new LinearRegressionFunction(thetaVector);
// create the feature vector function with x0=1 (for computational reasons) and x1=house-size
Double[] featureVector = new Double[] { 1.0, 1330.0 };
// make the prediction
double predictedPrice = targetFunction.apply(featureVector);
La línea de predicción de la función objetivo se muestra como una línea azul en la Figura 4. La línea se ha calculado ejecutando la función objetivo para todos los valores de tamaño de la casa. El gráfico también incluye los pares precio-tamaño utilizados para la formación.
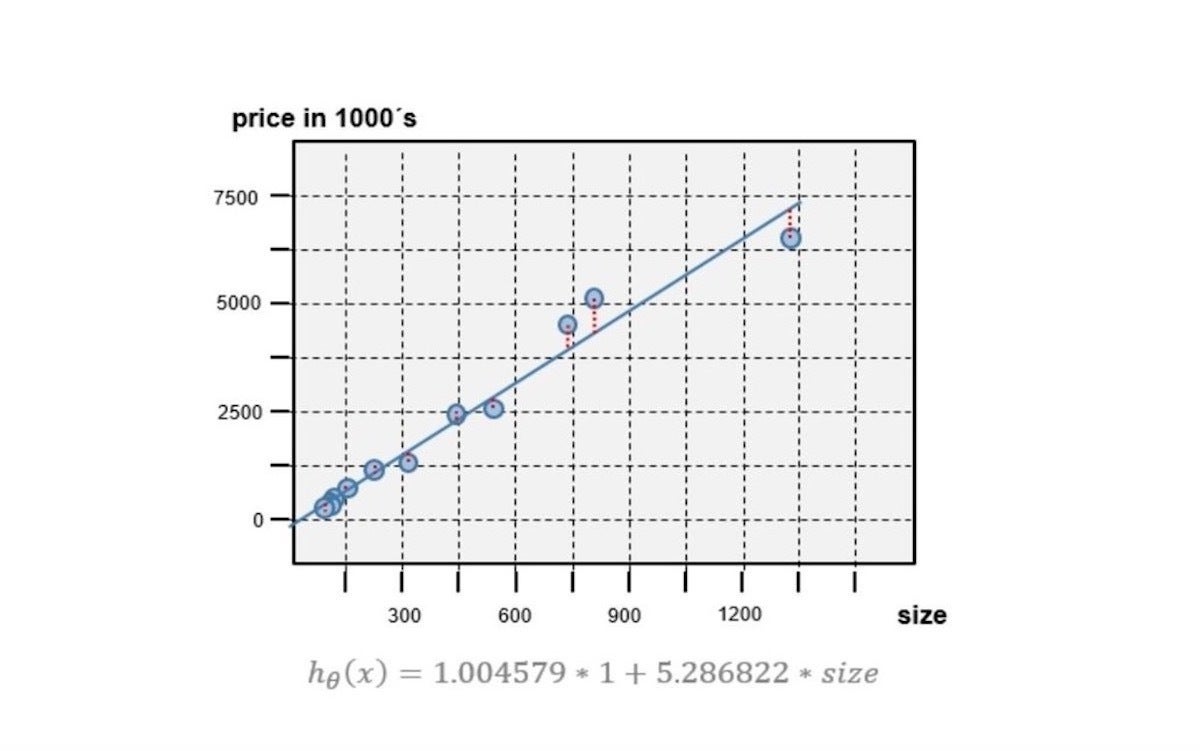 Gregorio Roth
Gregorio RothFigura 4. Línea de predicción de la función objetivo



